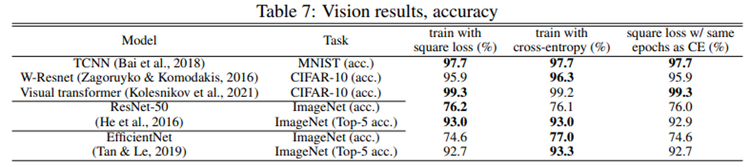
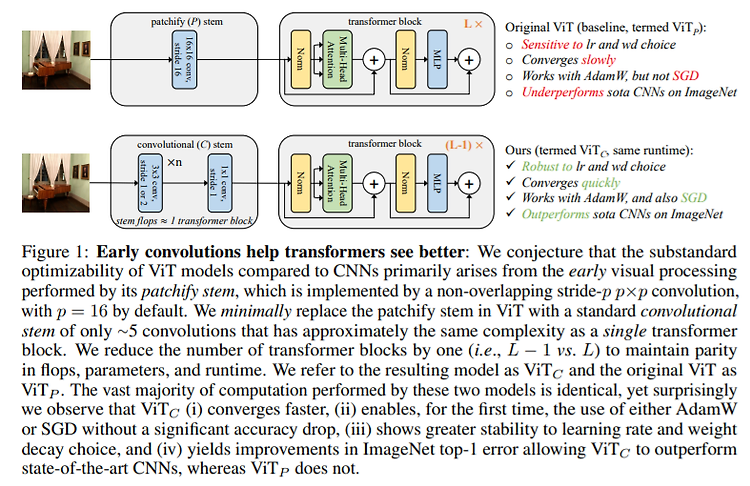
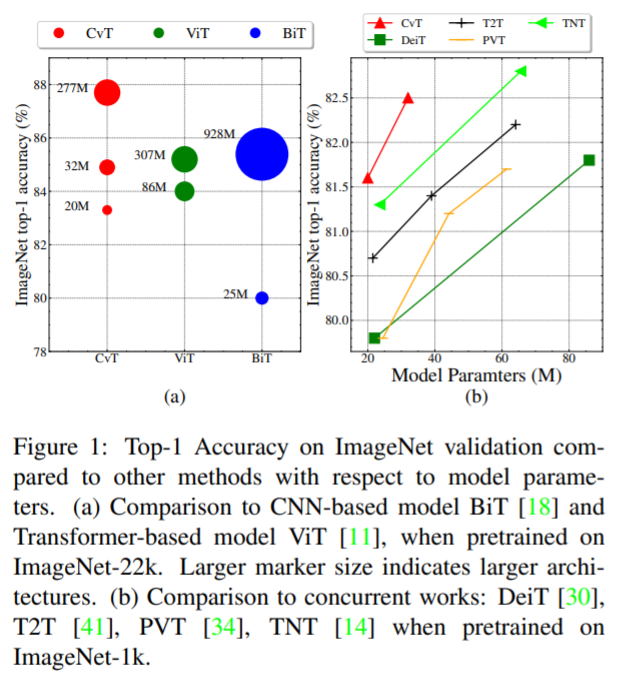
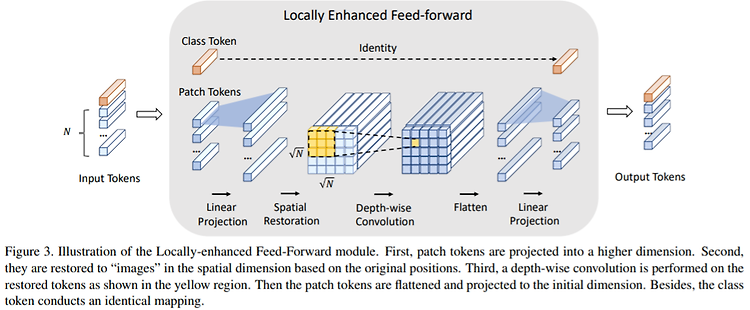
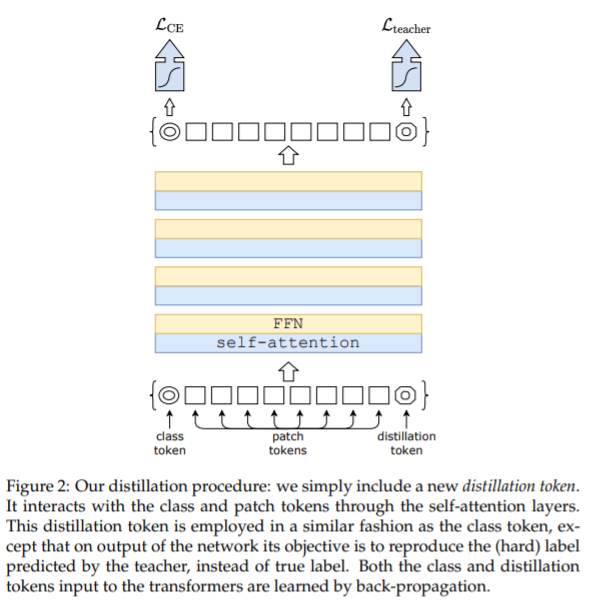
Evaluation of Neural Architectures Trained with Square Loss vs Cross-Entropy in Classification Tasks https://arxiv.org/abs/2006.07322 Evaluation of Neural Architectures Trained with Square Loss vs Cross-Entropy in Classification Tasks Modern neural architectures for classification tasks are trained using the cross-entropy loss, which is widely believed to be empirically superior to the square lo..