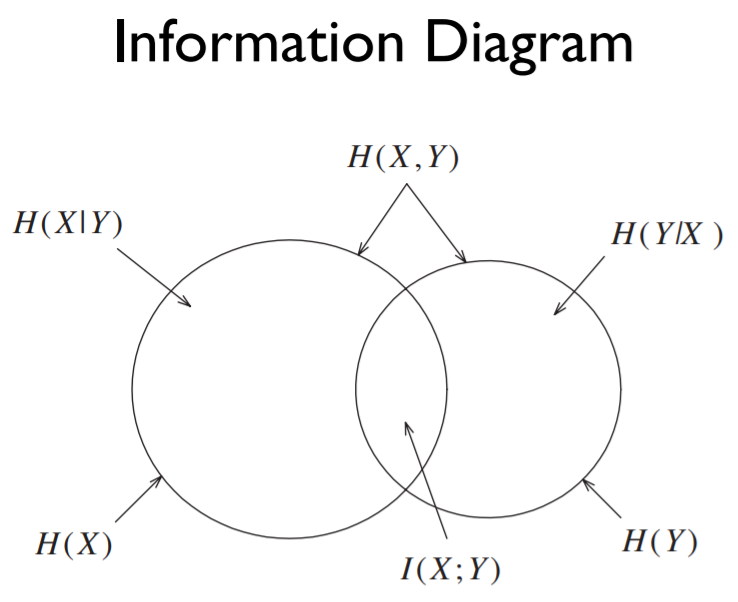
Chain Rule for Entropy 엔트로피에서도 연쇄 법칙이 성립합니다. 이전 포스팅에서의 entropy diagram을 생각해 보았을 때, H(1,2) = H(1) + H(2$\mid$1)은 당연합니다. Chain Rule for Conditional Entropy 조건부 엔트로피에 대해서도 연쇄 법칙이 성립합니다. Chain Rule for Mutual Information Chain Rule for Conditional Mutual Information 증명은 너무 어렵네요..ㅎㅎ 다른 증명입니다. 출처: Coursera Information Theory 강의 https://www.coursera.org/learn/information-theory/home/info Coursera | Onl..