이번에 소개할 논문은 'YOLO9000: Betterm Faster, Stronger' 입니다.
논문에서는 YOLO v2와 YOLO9000을 소개하고 있습니다.
YOLO v2는 YOLO v1을 개선한 버전이고, YOLO9000은 9000개의 카테고리를 탐지할 수 있도록 학습된 신경망입니다.
YOLO9000는 classification dataset 'ImageNet'과 detection dataset 'COCO' 를 동시에 학습시켰습니다.
어떤 방법으로 학습을 시켰고, YOLO v1에서 어떤 점을 개선시켰는지 알아보도록 하겠습니다.
논문은 3가지 파트로 나뉘어져 있습니다.
Better : YOLO v1에서 개선된 내용
Faster : YOLO v2의 신경망인 Darknet-19
Stronger : 9000개의 카테고리를 탐지하는 YOLO9000
Better
Better에서는 YOLO v1을 개선한 방법들을 소개합니다.
우선, YOLO v1의 단점에 대해서 말합니다.
(1) localization error가 많습니다.
YOLO v1은 다른 detection 기법과 비교해봤을 때, localization error가 많습니다. localization error는 바운딩 박스 위치를 제대로 포착하지 못하는 것을 말합니다.
(2) recall이 낮습니다.
region proposal-based 방법보다 recall이 낮습니다.
따라서 저자는 localization과 recall을 개선하는데 집중했다고 말합니다.
더 나은 성능을 얻기 위해서 신경망의 크기를 키우거나 모델을 앙상블 하는 방법이 주로 이용됩니다.
하지만 저자는 detector가 빠르게 작동하길 원합니다. 신경망의 크기를 키우는 대신에 신경망을 간소화하고 표현력을 쉽게 학습할 수 있도록 했습니다. 이를 위해 어떠한 방법을 활용했는지 알아보겠습니다.
1. Batch Normalization
Batch Normalization은 다른 regularization의 필요성을 없애고 신경망을 더 빠르게 수렴하도록 합니다. YOLO의 convolutional layer에 Batch Normalization을 이용하여 mAP를 2% 상승시켰고, dropout을 제거했습니다.
2. High Resolution Classifier
YOLO v1은 VGG16을 기반으로 입력 이미지 224x224로 학습을 했습니다. 하지만 detection을 할 때는 입력 이미지 448x448을 이용합니다. 224x224 이미지로 학습을 했는데, detection은 448x448 이미지로 수행을 하니, 성능이 떨어질 수 밖에 없었습니다.
이를 해결하기 위해 YOLO v2는 ImageNet dataset에서 448x448 이미지로 fine tuning을 해주었고, 해상도 이미지에 잘 작동할 수 있게 되었습니다. 그러고 나서 detection을 위한 fune tuning을 해줍니다.
고 해상도 이미지로 학습된 CNN 신경망은 4% mAP를 증가시켜주었습니다.
3. Convolutional With Anchor Boxes
YOLO v2는 fully connected layer를 제거하고 anchor box를 활용해서 바운딩 박스를 예측합니다. 1x1 convolutional layer로 예측을 하는 것입니다.
바운딩 박스의 좌표를 예측하는 것보다, 사전에 정의한 Anchor box에서 offset을 예측하는 것이 훨씬 간단하게 학습을 할 수 있기 때문입니다. 이를 위해서 두 가지 변화를 주었습니다.
(1) 한 개의 pooling layer를 제거했습니다.
pooling layer를 제거함으로써 convolutional layer의 출력을 고 해상도로 만들어 주었습니다.
(2) 입력 이미지 크기를 448에서 416으로 변경했습니다.
416을 32배로 down sampling 하면 13x13의 feature map이 얻어지고,
448을 32배로 down sampling하면 14x14의 feature map이 얻어집니다.
보통 물체가 이미지의 중앙에 있는 경우가 많기 때문에, 최종 output feature map을 홀수x홀수로 지정해주는 것이 좋다고 말합니다. 짝수로 설정하게 되면 중앙에 4개의 grid cell이 인접하기 때문입니다. 입력 이미지를 416으로 변경하여, 13x13 feature map이 얻어져 중앙에 하나의 grid cell이 위치하도록 합니다..
anchor box를 이용하여 mAP은 감소하고 recall이 증가합니다. recall이 상승하여 YOLO v2는 더 개선될 여지가 남아있다고 말합니다.
anchor box를 이용하지 않았을 때 69.5 mAP와 81% recall을 얻었고
anchor box를 이용했을 때 69.2 mAP와 88% recall을 얻었습니다.
4. Dimension Clusters
신경망은 Anchor box를 수정하면서 바운딩 박스를 예측합니다. 따라서 사전에 설정된 anchor box의 영향이 클 수 밖에 없고 신중하게 anchor box를 선택해야 합니다. 이를 해결하기 위해서 Anchor box를 training set의 바운딩박스에 k-means clustering을 사용하여 얻습니다.
일반적인 k-means clustering은 Euclidean distance을 이용합니다.
YOLO v2에서 Euclidean distance를 사용한 k-means clustering을 이용하면 문제가 발생합니다. 실제 바운딩 박스와 높은 IoU를 지닌 anchor box를 선정해야 하는데, 중심 좌표의 거리가 가장 짧은 것을 기준으로 anchor box를 선정하면, IoU가 낮은 anchor box를 선정할 수 있다는 것입니다.
이를 해결하기 위해서 IoU를 기준으로 k-means clustering을 사용합니다.

k-means clustering에서 하이퍼파라미터는 clustering의 개수 k입니다. 이 k는 속도와 정확도 균형을 고려해 5로 선정했습니다. 높은 k를 선택하면 높은 정확도를 얻을 수 있지만, 속도가 느려지기 때문입니다. 아래 그림은 k에 따른 평균 IoU 입니다.
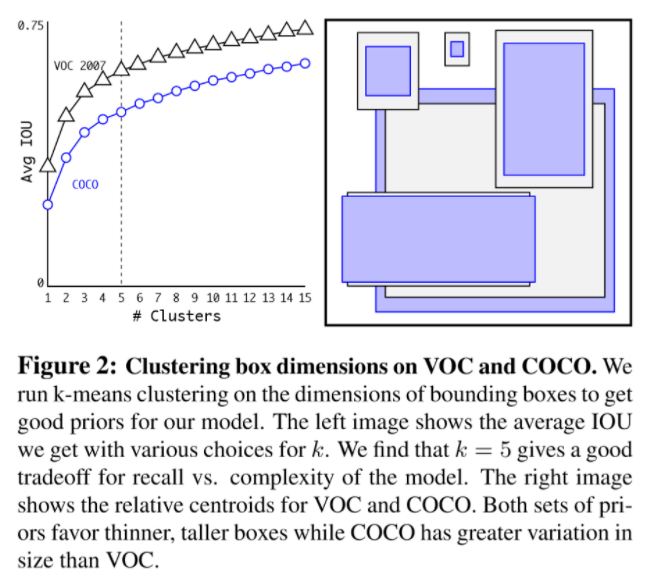
아래 표는 hand-picked anchor box와 clustering 방법을 비교한 표입니다. clustering 방법이 더 좋은 결과를 가져온다는 것을 확인할 수 있습니다.

5. Direct location prediction
anchor box를 활용한 바운딩박스 offset 예측법은 바운딩박스의 위치를 제한하지 않아서 초기 학습시 불안정하다는 단점이 있습니다. 예측값의 범위를 제한하지 않으면 바운딩 박스가 이미지 어디에도 나타날 수 있습니다. 안정적으로 바운딩박스를 예측하기 까지 모델이 학습되는데에는 많은 시간이 걸리게 됩니다.
위 문제를 해결하기 위해 sigmoid 함수를 활용하여 offset의 범위를 0에서 1로 제한합니다.
모델은 각 바운딩 박스마다 5개의 값 ($t_x, t_y, t_w, t_h, t_o$)을 예측합니다. 수식은 다음과 같습니다.


$c_x$ : 좌측 상단에서 grid cell의 x좌표
$c_y$ : 좌측 상단에서 grid cell의 y좌표
$p_w$ : 이전 바운딩 박스의 너비
$p_h$ : 이전 바운딩 박스의 높이
바운딩박스 중심 좌표 예측값($t_x, t_y$)을 시그모이드 함수로 감싸 바운딩박스의 위치를 제한하여 안정적으로 학습이 됩니다.

바운딩박스 clustering과 이 방법을 활용하여 성능이 5% 향상되었습니다.
6. Fine-Grained Features
YOLO v2는 13x13 feature map을 출력합니다.
13x13의 크기는 큰 물체를 검출할 때는 충분하지만, 작은 물체를 검출할 때는 불충분 합니다.
Faster R-CNN과 SSD는 다양한 크기의 feature map에서 영역을 제안하여 문제를 해결합니다.
YOLO v2는 다르게 접근합니다.
passthrough layer를 추가하여 이전 layer의 26x26 feature map을 가져옵니다.
가져온 26x26 feature map을 13x13 feature map에 이어 붙입니다.
feature map의 크기가 다르므로 그냥 이어붙일 수 없습니다.
26x26x512의 feature map을 13x13x(512*4)의 feature map으로 변환하여 붙입니다.
26x26 크기의 feature map에 고 해상도 특징이 담겨 있으므로 이 정보를 활용하는 것입니다.
이 방법으로 1%의 성능 향상이 있습니다.
7. Multi-Scale Training
YOLO v2는 다른 크기의 이미지로부터 robust를 갖기 위해 다양한 크기로 학습합니다.
매 10epoch마다 {320, 352, ..., 608} 크기로 학습합니다. YOLO v2는 입력 사이즈에 32배 down sampling하기 때문에 간격을 32로 설정했습니다. {320, (320+32), (320+32+32), ... ,608} 따라서 다양한 입력 크기에도 예측을 잘할 수 있습니다.
또 입력 크기를 변경하여 YOLO v2를 구동하면 속도와 정확도 trade off를 조절할 수 있습니다.
작은 입력 크기로 YOLO v2를 실행하면 빠르고 덜 정확하게 예측할 수 있고, 높은 입력 크기로 YOLO v2를 실행하면 느리고 정확하게 예측할 수 있습니다.
이처럼 상황에 맞게 YOLO v2를 실행할 수 있습니다.
8. Performance
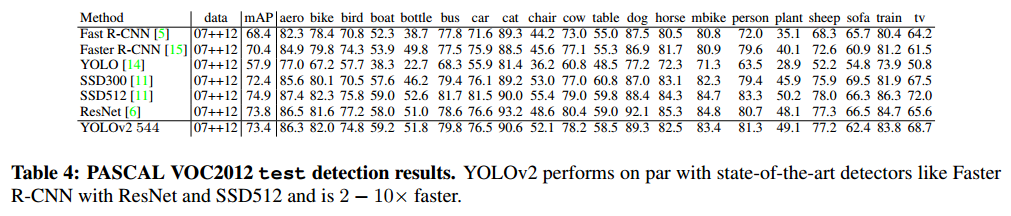
아래 표는 다른 기법들과 YOLO v2를 비교한 표입니다.


Faster
Faster에서는 YOLO v2에서 사용하는 신경망인 Darknet-19를 소개합니다.
많은 detection 방법들이 VGG-16을 사용합니다. VGG-16은 강력하고 정확하지만 연산량이 많습니다. 빠른 속도를 지향하는 YOLO v2는 새로운 신경망인 Darknet-19를 구축하여 이용합니다.
Darknet-19
Darknet-19는 19개 convolutional layer와 5개 maxpooling layer로 구성됩니다.
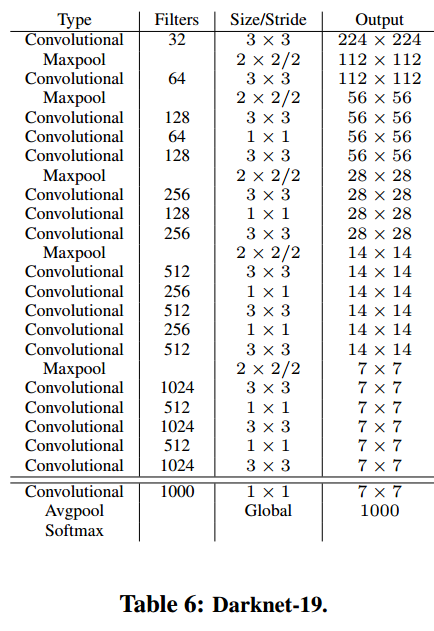
VGG model에서 사용한 3x3 filter와 GoogLeNet에서 이용된 NIN(Network in Network) 기법을 사용합니다.
3x3 filter 사이에 1x1 filter로 차원축소와 FC layer 제거하여 연산량을 줄입니다.
Stronger
Stronger에서는 YOLO9000을 소개합니다. 9000개의 category를 검출할 수 있어서 YOLO9000라고 합니다.
YOLO9000은 classification data와 detection data를 동시에 학습시킨 것입니다.
detection data로 바운딩 박스 좌표와 objectness 같은 정보를 학습하고 classification data로 class label을 학습하여 검출할 수 있는 카테고리의 수를 확장합니다.
classification data가 입력되면 classification loss만을 계산하고 detection data가 입력되면 원래 loss를 계산합니다.
두 종류의 data를 학습하는 것은 몇 가지 어려움이 있었습니다.
(1) Detection dataset과 Classification dataset의 label이 다릅니다.
detection dataset은 일반적이고 적은 범위의 label을 갖습니다.(dog, boat, cat)
classification dataset은 더 넓고 깊은 label을 갖습니다.(여러 종류의 개, Nortfolk terrier, Yorkshire terrier, Bedlington terrier)
이 두 label을 병합하기 위한 일관성있는 방법을 찾아야 합니다.
(2) 최종 class 확률을 계산할 때, 각 class가 상호 배타적(mutually exclusive)로 가정합니다.
두 dataset을 결합하면 detection data label인 dog와 classification data label인 Nortfolk terrier는 상호 배타적이지 않습니다.
따라서 multi-label model을 사용하여 상호 배타를 가정하지 않습니다.
이제 어떤 방법으로 두 dataset을 결합하고 학습시켰는지 알아보겠습니다.
1. Hierarchical classification
이미지넷(ImageNet)의 label은 워드넷(WordNet)의 구조에 따라 정리되어 있습니다.
워드넷의 구조를 보면 Norfolk terrier와 Yorkshire terrier는 terrier의 하위어, terrier는 hunting dog의 하위어, hunting dog는 dog의 하위어, dog는 canine의 하위어 입니다. 정리를 하면 Norfolk terrier, Yorkshire terrier < terrier < hunting dog < dog < cannie가 됩니다.
워드넷은 트리(Tree)가 아니라 유향 그래프(directed graph)로 구현되어 있습니다. 언어는 복잡하기 때문입니다.
YOLO v2는 그래프 구조 대신 트리 구조를 구축하여 사용합니다.
'물리적 오브젝'의 경우에 이미지넷에서 명사가 워드넷 그래프의 루트로부터 어느 경로에 나타나는지 조사했습니다.
많은 명사들이 그래프에서 하나의 경로만 갖으므로, 그것들을 모두 트리에 추가합니다. 그리고 가능한한 조금씩 경로를 추가하면서 트리를 키웁니다. 루트에서 특정 노드까지의 경로가 여러개일 경우에는 가장 짧은 경로를 선택합니다.
최종적으로 워드트리(WordTree)를 만들었습니다.
워드트리에서 예측을 하기 위해 조건부확률을 계산합니다. 모든 노드에서 주어진 관련어의 조건으로 하의어 확률을 계산하는 것입니다. 예를 들어 terrier 노드에서는 다음을 계산합니다.

특정 노드에서 확률을 구하고 싶을 때는 트리의 경로를 따라서 모든 노드의 조건부 확률을 곱합니다. 예를 들어, Norfolk terrier의 확률은 다음과 같이 계산합니다.

이미지넷에서 1000개 class를 사용하여 구축한 워드트리로 Darknet-19를 학습합니다.
워드트리1k를 구축하기 위해 중간 노드를 추가하여 label은 1000개에서 1369개로 확장됬습니다.
학습 과정에서 실제 label을 트리의 루트까지 전파시킵니다. 따라서 이미지가 Norfolk terrier 를 갖고 있으면, dog와 mammal 레이블도 얻게 됩니다.
조건부확률을 계산하기 위해서 1369개의 벡터를 예측하고, 모든 같은 개념의 하의어를 갖는 관련어에 대한 softmax를 계산합니다. 하나의 softmax를 계산하는 것이 아니라 아래 그림처럼 동의어에 대해 폭이 다양한 여러 개의 softmax를 계산합니다.
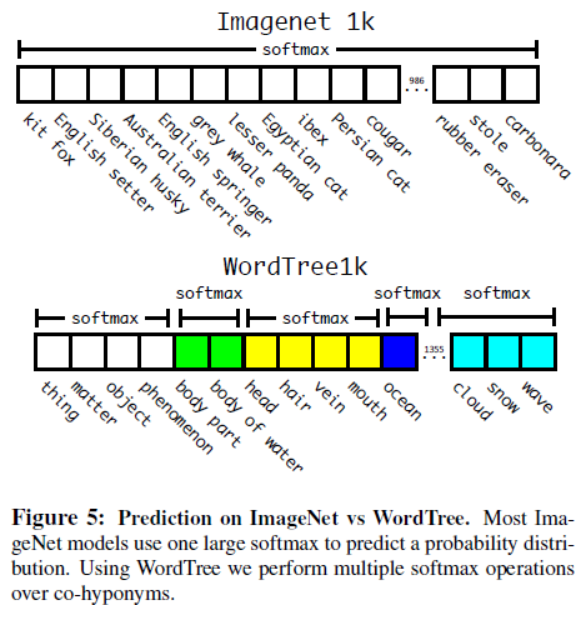
이렇게 학습된 Darknet-19는 369개념이 추가됬지만 성능이 하락했습니다.
이 방법으로 classification를 수행하면 이점이 있습니다.
dog 이미지를 보여줬을 때, 가장 높은 confidence로 dog를 예측하고, 낮은 confidence로 하의어를 예측합니다.
detection을 수행하면 바운딩박스를 예측하고 확률의 트리를 얻습니다. 이 트리를 따라 내려가다가 갈라지는 곳에서 높은 confidence를 지닌 경로를 선택합니다. 임계점에 도달할때 까지 반복하고, 해당 class를 예측합니다.
2. Dataset combination with WordTree
COCO dataset과 ImageNet dataset을 결합하기 위해 워드트리를 사용했습니다. dataset에 있는 범주와 트리에 있는 관련어를 간단하게 연결했습니다. 아래 그림은 워드트리의 예시입니다.
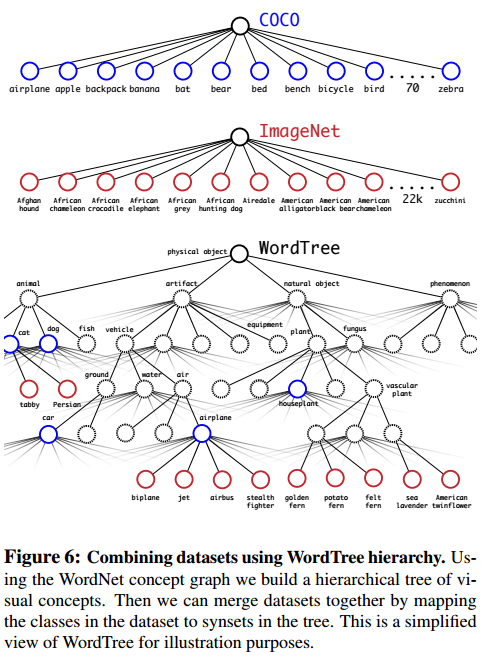
3. Joint classification and detection
이제 워드트리로 모델을 학습합니다.
COCO dataset과 ImageNet 9000개 클래스를 결합하여 9418개 클래스를 지닌 워드트리를 생성합니다.
이미지넷이 코코보다 데이터가 훨씬 많기 때문에 코코 데이터셋을 4:1 비율로 oversampling 합니다.
출력 사이즈의 한계 때문에 5개가 아닌 3개의 prior을 사용하여 YOLO9000을 학습합니다.
detection 이미지를 보면 평소대로 loss를 계산하고 classification loss는 해당 클래스와 그것의 상위 클래스에 대해서만 역전파 합니다.
예를 들어 label이 'dog'이면 트리의 더 아래쪽에 있는 예측에도 오류를 할당하여 더 아래로 내려갈 수 있도록 합니다.
이렇게 결합 학습으로 YOLO9000은 COCO data를 사용하여 객체를 찾아내고 ImageNet data를 사용하여 이 객체를 classification 합니다.
참고자료
'논문 읽기 > Object Detection' 카테고리의 다른 글
| [논문 읽기] Fast R-CNN(2014) 리뷰 (1) | 2021.02.14 |
|---|---|
| [논문 리뷰] SPPnet (2014) 리뷰, Spatial Pyramid Pooling Network (5) | 2021.02.10 |
| [논문 리뷰] YOLO v1 (2016) 리뷰 (4) | 2021.02.02 |
| [논문 리뷰] R-CNN (2013) 리뷰 (14) | 2021.01.04 |
| [Object Detection] mAP(mean Average Precision)을 이해하고 파이토치로 구현하기 (3) | 2021.01.03 |