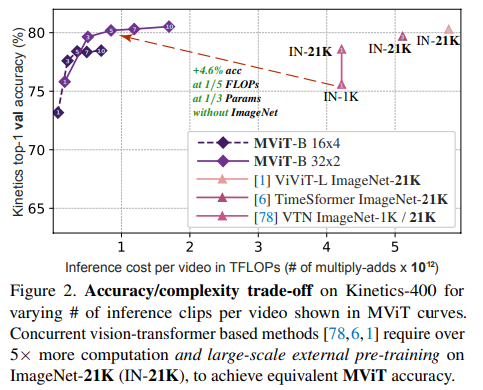
Towards Training Stronger Video Vision Transformers for EPIC-KITCHENS-100 Action Recognition PDF, VIdeo Recognition, Ziyuan Huang, Zhiwu Qing, Xiang Wang, Yutong Feng, Shiwei Zhang, arXiv 2021 Summary 해당 논문은 21.06에 arxiv에 올라온 논문입니다. Video Recognition 모델을 EPIC-KITCHENS-100 데이터셋에 여러가지 학습 방법을 실험합니다. 모델을 학습시킬시에 여러 가지를 고려해야 하는데 이 논문이 참고 사항이 될 수 있을 것 같네요 ㅎㅎ 우선 ViViT를 kinetics400, 700, SSV2로 pre-train ..