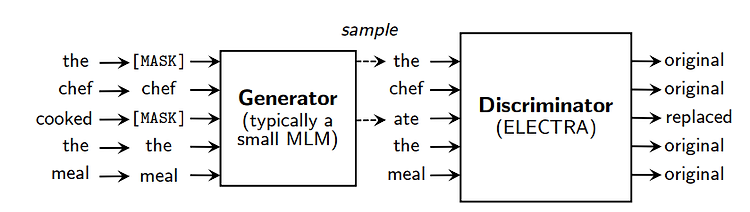
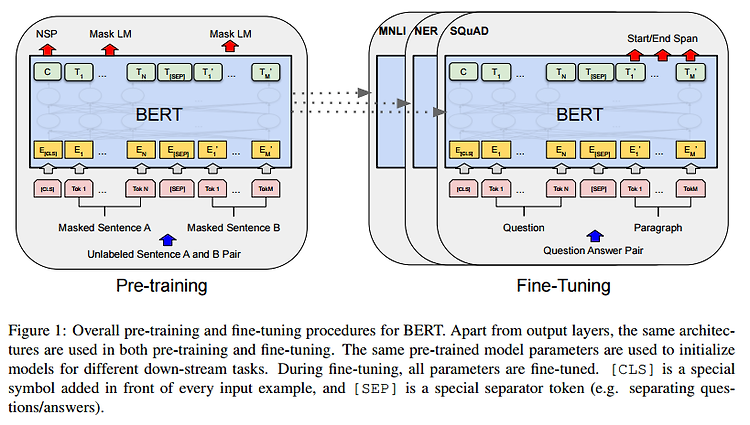
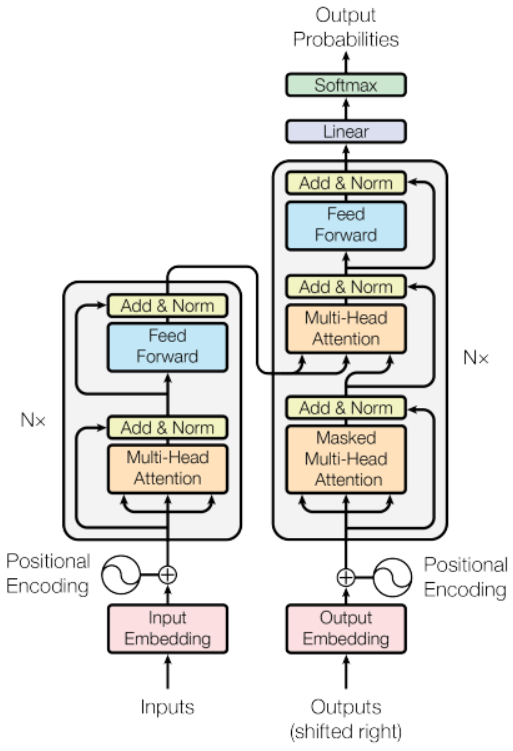
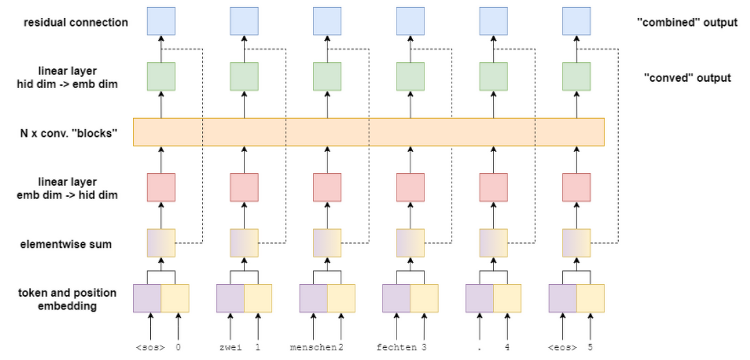
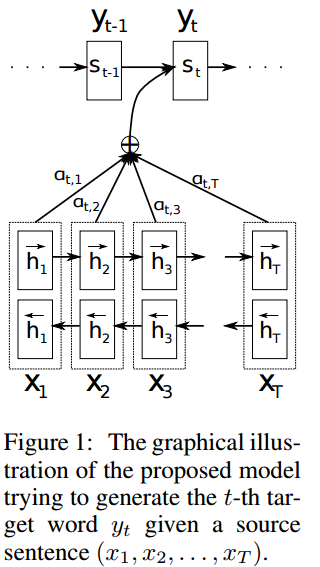
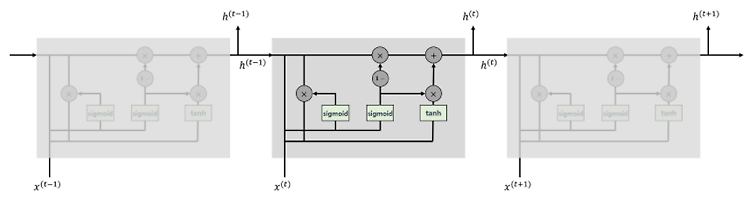
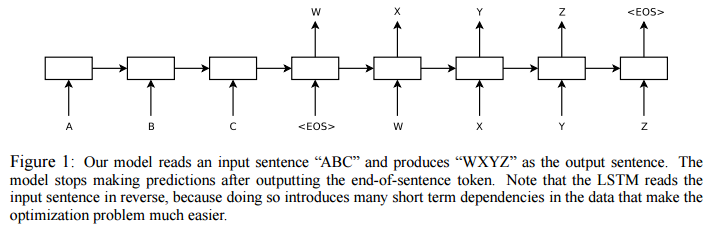
ELECTRA: Pre-Training Text Encoders as Discriminators Rather Than Generators https://arxiv.org/abs/2003.10555 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results ..