ELECTRA: Pre-Training Text Encoders as Discriminators Rather Than Generators
https://arxiv.org/abs/2003.10555
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, the
arxiv.org
Summary
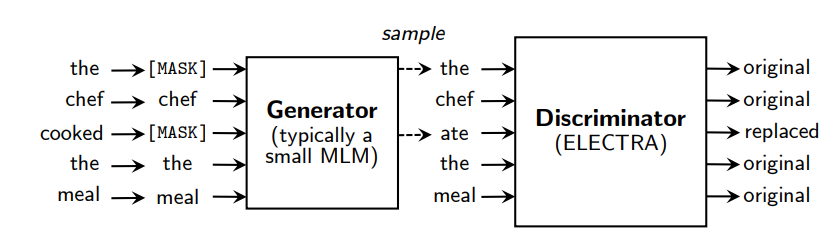

문장에서 단어를 masking 하여 generator로 전달한다. generator는 일반적인 MLM 모델이며 mask된 단어를 예측하는 태스크를 수행한다. 따라서 loss는 maximum likelihood를 최대화 하는 방향으로 학습이 진행된다.

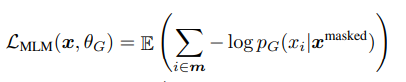
Discriminator는 generator가 생성한 단어인지, 원래의 단어인지 구분하는 task로 학습이 진행된다. 출력값은 sigmoid 연산을 통해 0 또는 1의 값만 출력한다.

이렇게 학습한 모델은 generator를 버리고 discriminator를 downstream task로 fine tunning하여 사용한다.
논문에서 말하는 두 가지 장점
(1) compute efficiency하다.
왜? bert는 mask된 단어는 학습에 이용되지 않지만(MLM) electra는 모든 개별 단어(LM)를 입력 받는다고 한다. 이게 왜 compute efficiency 하지? 사용할 수 없는 데이터가 생겨서 그런건가?
(2) BERT의 pre train과 fine-tuning의 mismatch를 완화한다.
pre-train은 masked 된 토큰만을 보는데 fine-tunning시에는 그렇지 않다.
https://github.com/Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch
GitHub - Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch: 공부 목적으로 논문을 리뷰하고 해당 논문 파
공부 목적으로 논문을 리뷰하고 해당 논문 파이토치 재구현을 합니다. Contribute to Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch development by creating an account on GitHub.
github.com