안녕하세요! 이번에 읽어볼 논문은 2019년에 등장한 EfficientNetV1의 후속작 EfficientNetV2, Smaller Models and Faster Training 입니다.
EfficientNetV2는 빠른 학습에 집중한 모델입니다. 데이터셋의 크기가 커질수록 빠른 학습의 중요성도 높아지는데요. 자연어 처리 분야에서 GPT-3은 엄청 큰 데이터셋으로 학습시켜서 뛰어난 성능을 보이고 있습니다. 하지만 GPT-3은 수천개의 TPU로 몇주일간 학습시켰기 때문에 retrain과 개선이 어렵다는 단점이 있습니다. training efficiency는 최근에 큰 관심을 받고 있는데요. 예를 들어, NFNet(2021), BotNet(2021), ResNet-Rs(2021) 등 모두 training efficiency를 향상시키기위해 제안된 모델입니다. 앞에서 설명한 모델들과 EfficientNetV2의 parameters수를 비교했을 때, EfficientNetV2의 parameter수가 월등히 적은데요. 그만큼 효율적인 모델인 것을 강조하고 있네요.

위 그림을 보면, EfficientNetV2는 EfficientNetV1와 비교했을 때 4배 빠른 학습속도와 6.8배 적은 parameter수로 비슷한 정확도를 달성합니다.
논문에서 학습 속도를 느리게 하는 3가지 요소를 설명합니다. (1) 큰 이미지로 학습을 하면 학습 속도가 느립니다. (2) 초기 layer에서 depthwise convolution은 학습 속도에 악영향을 줍니다. (3) 모든 stage를 동일한 비율로 scailing up하는 것은 최적의 선택이 아닙니다. 이 3가지를 해결하기 위해서 progressive learning과 fused-MBConv, non-uniform scaling 전략을 소개합니다.
(1) Training with very large image sizes is slow
큰 입력 이미지로 학습을 하면, 메모리가 제한되어 있기 때문에 batch size를 작게 해야 합니다. 따라서 학습 속도가 느려지게 됩니다. 입력 이미지를 작게 하는 것은 연산량을 감소시키고 큰 batch size를 사용할 수 있게 합니다. 또한 FixEfficientNet에서 train 입력 이미지를 test 입력 이미지보다 작게 학습하여 성능을 향상시켰었습니다. EfficientNetV2는 좀 더 나은 학습 방법인 Progressive Learning을 제안합니다.
Progressive Learning
Progressive Learning은 training할 때, 이미지의 크기를 점진적으로 증가시키는 것입니다. 이 방법은 학습 속도를 빠르게 하기 위해 사용하지만 정확도가 감소한다는 문제점이 있었습니다. 기존의 방법은 입력 이미지 크기에 따라 모두 동일한 정규화(dropout, augmentation)를 적용했지만, EfficientNet은 이미지 크기에 따라 정규화 방법을 다르게 설정하여 정확도가 감소하는 문제점을 해결합니다.
저자는 progressive learning을 적용했을 때, 정확도가 감소하는 이유는 입력 이미지 크기에 따라 동일한 정규화를 사용하기 때문이라고 합니다. 따라서 입력 이미지가 작을 때는 약한 정규화, 입력 이미지가 클 때는 오버 피팅을 방지하기 위해 강한 정규화를 적용합니다. 예를 들어, 입력 이미지가 작으면 augmentation 확률을 낮게 설정하고 입력 이미지가 크면 augmentation 확률을 좀 더 높게 설정하거나 dropout 확률을 높이는 것입니다.

아래 표는 실험 결과 입니다. 입력 이미지가 커질 수록 RandAug magnitude를 높게 설정하면, 성능이 향상되는 것을 확인할 수 있습니다.
논문에서는 3가지 정규화를 사용합니다. (1). Dropout, (2) RandAugment, (3) Mixup

ImageNet dataset에 적용하는 Progressive training setting 입니다. 입력 이미지가 커질수록 최소값에서 최대값으로 점진적으로 증가합니다.
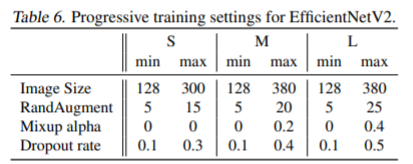
progressive learning 적용 방법은, training 과정을 4stage로 나눕니다. 1stage당 87epochs를 진행하며, stage를 지날 수록 입력 이미지 크기와 정규화 강도를 높입니다.
progressive learning을 다른 모델에 적용해도 성능이 향상됩니다.

(2) Depthwise convolutions are slow in early layers

Depthwise convolution은 MobileNetV1와 Xception에서 제안된 방법입니다. 그리고 효과가 입증되어 최신 모델까지 이용하고 있습니다. 이 Depthwise convolution은 conv 연산량을 낮춰주어 제한된 연산량 내에 더 많은 filter를 사용할 수 있는 이점이 있습니다. 하지만 Depthwise convolution은 modern accelerator를 활용하지 못하기 때문에 학습 속도를 느리게 합니다. 따라서 stage 1-3 에서는 MBConv 대신에 Fused-MBConv를 사용합니다. Fused-MBConv는 MBConv의 1x1 conv + 3x3 depthwise conv 대신에, 하나의 3x3conv를 사용하는 것입니다. 모든 stage에 Fused-MBConv를 적용하니 오히려 학습 속도가 느려졌다고 합니다. 따라서 초기의 stage에만 Fused-MBConv를 사용합니다.
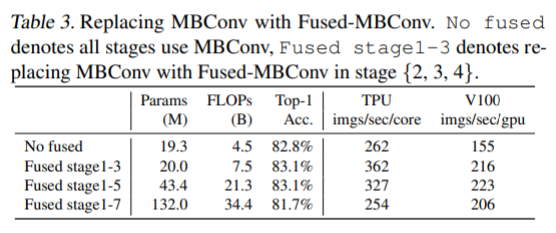
(3) Equally scaling up every stage is sub-optimal
EfficientNet은 compound scaling으로 모든 스테이지를 동일하게 scaling up을 했습니다. 예를 들어, depth 상수가 2이면 모든 stage의 layer가 2배가 되었었죠. 하지만 stage들이 training speed에 기여하는 정도가 다 다르다고 합니다. 따라서 non-uniform scaling strategy를 사용합니다. non-uniform scaling strategy는 stage가 증가할 수록 layer가 증가하는 정도를 높인 것입니다. 증가하는 정도는 heuristic하게 결정합니다. 추가적으로, compound scaling에서 maximum 이미지 사이즈를 작은 값으로 제한합니다. 그 이유는 progressive learning은 학습이 진행될 수록 입력 이미지 크기가 커지므로 memory 사용량이 점점 커져 학습 속도를 느리게 하는 문제를 해결하기 위함입니다.
EfficientNetV2 Architecture

Performance
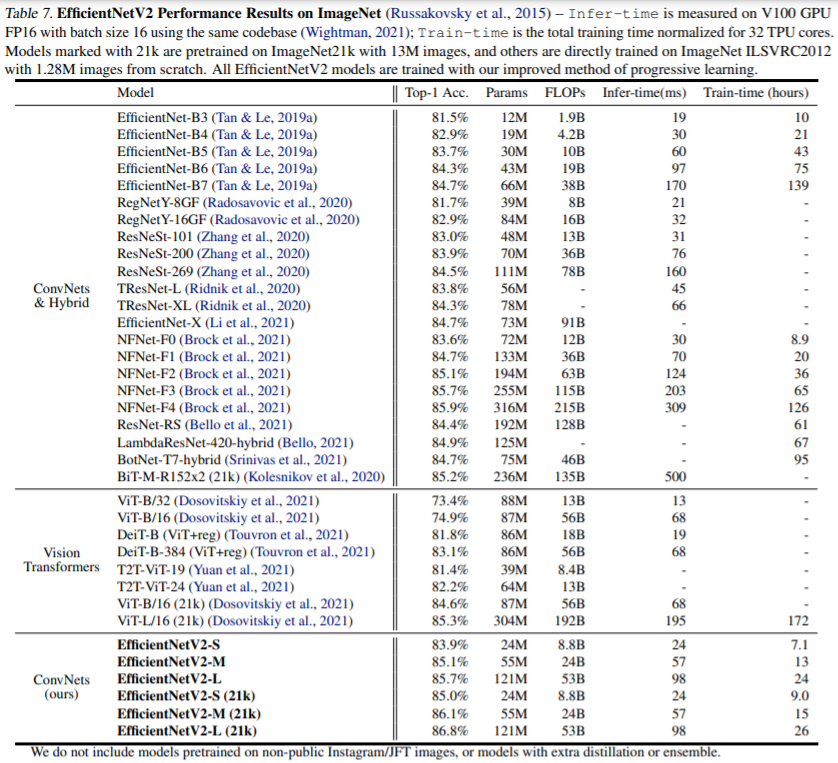


참고자료