반응형
안녕하세요, 오늘 읽은 논문은 Mish, A Self Regularized Non-Monotonic Activation Function 입니다.
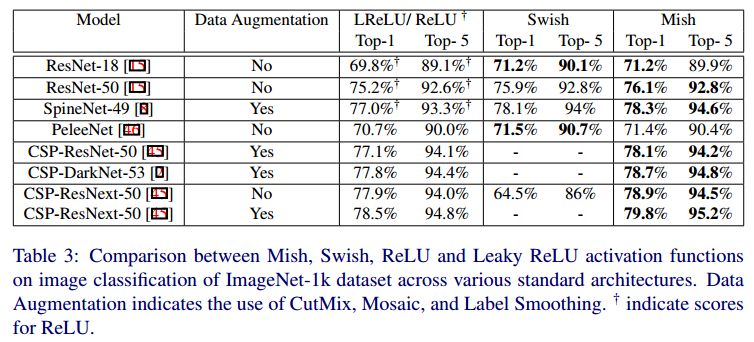
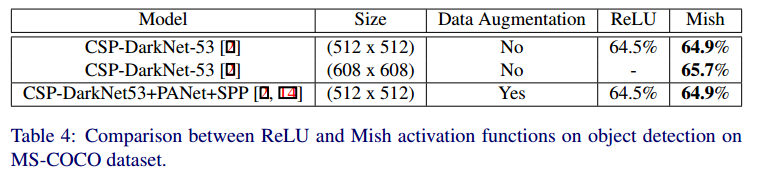
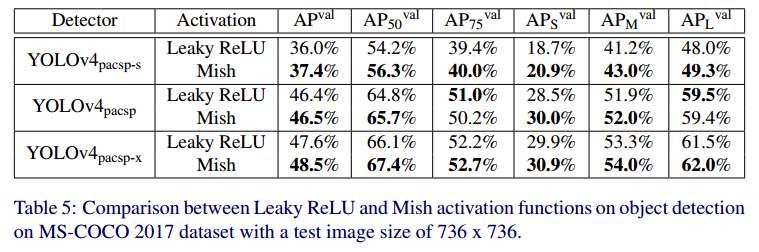
Mish는 Computer Vision 딥러닝 구조에서 Swish, ReLU, Leaky ReLU 보다 좋은 성능을 타나냅니다.

Mish
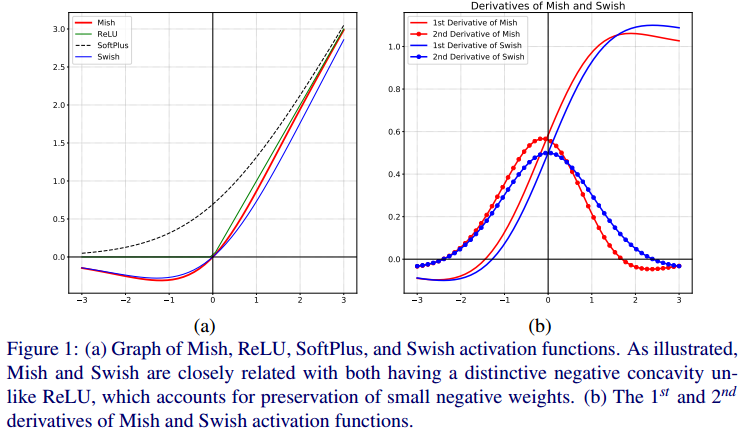
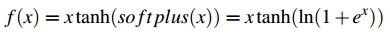
Mish는 smooth, continuous, self-regularized, non-monotonic한 속성을 갖고 있습니다.
Mish 특징
- ReLU는 음의 값을 가진 입력값을 0으로 만들기 때문에, 정보 손실이 발생하는 문제점이 있습니다. Mish는 작은 음의 값을 허용하여 더 나온 표현력과 정보 흐름을 돕습니다.
- Mish는 양의 값에 대해서 제한이 없기 때문에 saturation을 방지합니다. 이는 기울기 소실로 인해 발생하는 학습 지연 문제를 해결합니다.
- Mish의 출력값 범위는 [-0.31, 무한] 입니다. 음의 값이 -0.31로 제한되기 때문에 강력한 정규화 효과가 있습니다.
- ReLU와 달리 Mish는 연속적으로 미분이 가능하여 singularity(특이점)를 방지합니다. ReLU 함수는 연속적으로 미분이 불가능한 함수이며, 음의 값을 입력받는 경우에 미분 값을 무시합니다. 이와 달리 Mish는 연속적으로 미분이 가능하여 기울기 기반 최적화를 수행할 때, 부수적인 효과를 갖습니다.
- Loss 값이 smoothing 되는 효과가 있습니다.

Loss 값을 시각화한 그림입니다. (b) Mish의 Loss값이 부드럽게 형성되어 있어 더 쉬운 최적화와 더 나은 일반화를 돕습니다. 또한 넓은 minima 구역을 갖고 있으며, 가장 낮은 loss값을 갖습니다.
Mish가 Swish보다 좋은 성능을 갖는 이유
Mish는 Swish와 비슷한 형태를 갖고 있으며, Swish보다 더 좋은 효과를 나타냅니다. 왜 Swish보다 좋은 성능을 나타내는지에 대해서 논문은 다음과 같이 설명합니다.
Mish를 미분하면 아래와 같이 됩니다.
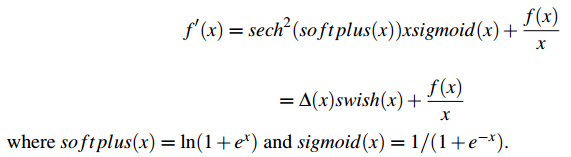
Swish(x) 앞에 존재하는 $\triangle (x)$ 값이 전제조건으로 작용하여 강력한 정규화 효과를 제공하고 gradient를 smoother 하게 만든다고 설명합니다. 이것이 Mish가 Swish보다 좋은 성능을 나타내는 이유라고 말합니다.
PyTorch Code
def mish(x):
return x * torch.tanh(F.softplus(x))참고자료
반응형