https://arxiv.org/abs/2112.01071
DenseCLIP: Extract Free Dense Labels from CLIP
Contrastive Language-Image Pre-training (CLIP) has made a remarkable breakthrough in open-vocabulary zero-shot image recognition. Many recent studies leverage the pre-trained CLIP models for image-level classification and manipulation. In this paper, we fu
arxiv.org
CLIP을 segmentation에 적용한 논문.
clip이 학습한 정보를 segmentation에 적용할 수 있을까?
clip은 classification task를 목적으로 설계되었기 때문에 image로부터 feature를 추출하고 global average pooling을 통해 하나의 벡터를 뽑아내 classifier로 전달한다.
그러면 global average pooling 이전의 feature map에서 각각의 cell은 token에 해당하는 정보를 갖고 있지 않을까?
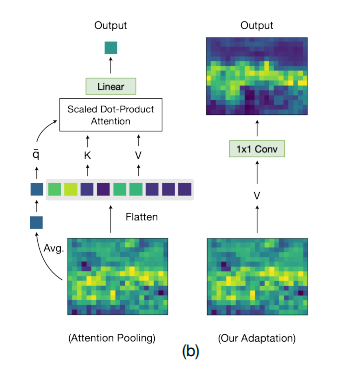
average pooling과 FFN을 제거하고 1x1 conv를 통해 곧바로 segemtation을 수행해본다. 1x1 conv는 text encoder가 추출한 word에 대한 representation을 가중치로 사용.
이렇게 재구성한 모델은 general한 성능을 갖게 되는데. 이로는 부족하다. clip의 image encoder는 segmentation에 적합한 모델이 아니기 때문.
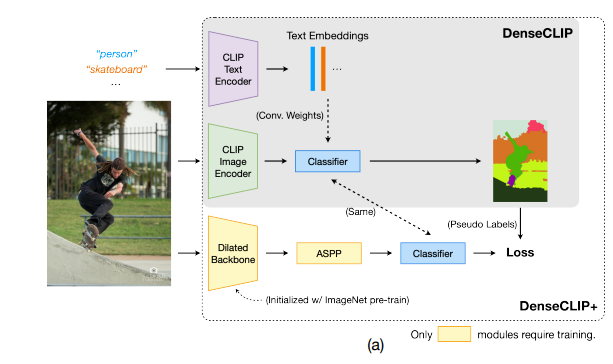
그래서 재구성한 모델(DenseCLIP)의 출력값을 pseudo label로 사용하여 segmentation model(deeplab or pspnet)을 학습시켰더니 성능이 잘나왔다. 여기에 self training까지 더하면 supervision으로 학습한 모델만큼의 성능을 달성함.


supervision으로 학습된 모델의 성능에 도달했는데 이 분야는 saturation 된걸까?
self-training 없이 성능을 높여보자.

GitHub - Seonghoon-Yu/AI_Paper_Review: 논문을 읽고 블로그에 정리합니다. 정리한 내용을 공유합니다.
논문을 읽고 블로그에 정리합니다. 정리한 내용을 공유합니다. Contribute to Seonghoon-Yu/AI_Paper_Review development by creating an account on GitHub.
github.com