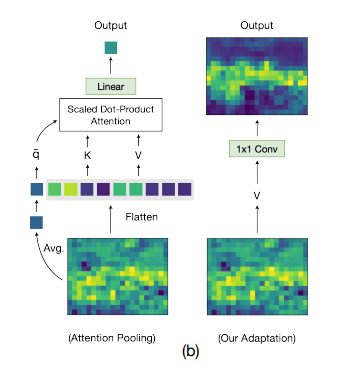
https://arxiv.org/abs/2112.01071 DenseCLIP: Extract Free Dense Labels from CLIP Contrastive Language-Image Pre-training (CLIP) has made a remarkable breakthrough in open-vocabulary zero-shot image recognition. Many recent studies leverage the pre-trained CLIP models for image-level classification and manipulation. In this paper, we fu arxiv.org CLIP을 segmentation에 적용한 논문. clip이 학습한 정보를 segmentat..