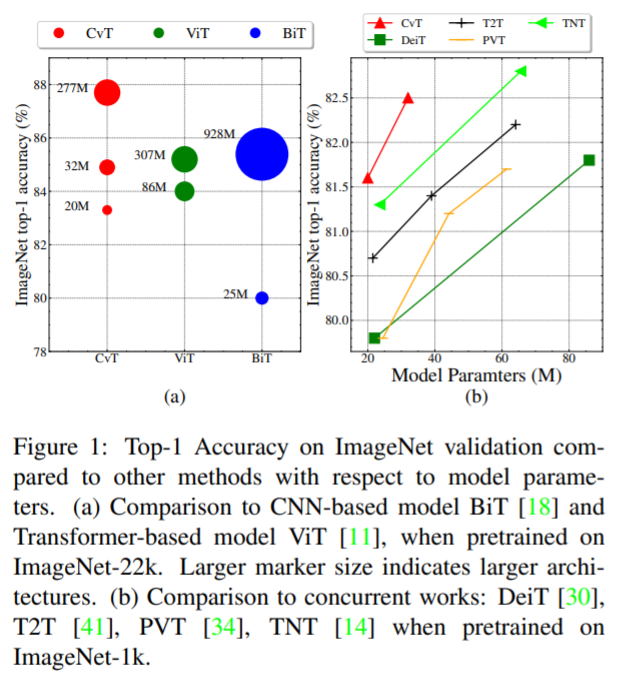
CvT: Introducing Convolutions to Vision Trnasformers Haiping Wu, Bin Xiao, Noel Codella, Mencgen Liu, Xiyang Dai Lu, Yuan Lei Zhang, arXiv 2021 PDF, Vision Transformer By SeonghoonYu August 8th, 2021 Summary CvT는 기존 CNN 구조에서 활용하는 계증 구조(hierarchical architecture)를 ViT에 적용한 논문입니다. 계층 구조를 형성할 수 있다면 low-layer에는 edge와 같은 low-level feature를 학습하고 높은 layer에서는 high-level feature을 학습할 것입니다. Vision Transfo..