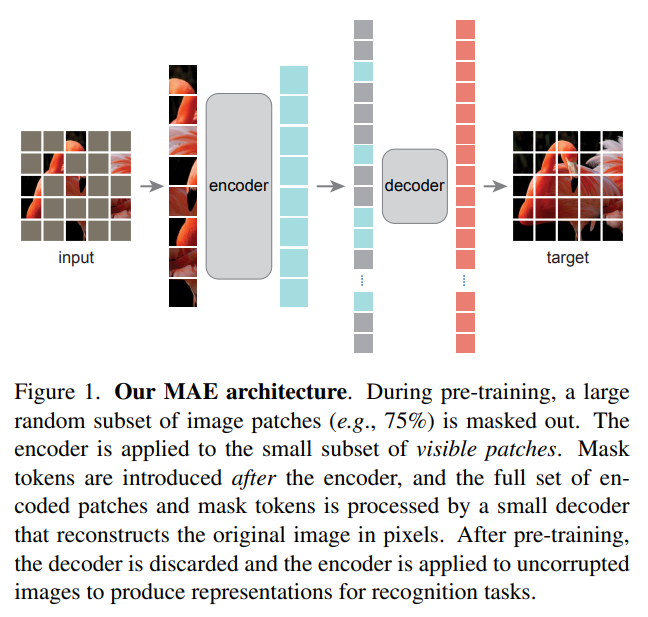
Masked Autoencoders Are Scalable Vision Learners PDF, Self-supervised Learning, He, et al, arXiv 2021 Summary 이미지를 패치로 짤라서 패치의 일부분을 mask 한다. mask 되지 않은 패치를 encoder로 입력하여 latent representation을 추출한다. 이 latent representation에 mask token을 추가하여 decoder로 전달한다. decoder은 mask token을 채우는 reconstruction 태스크를 수행한다. 인코더와 디코더 각각의 입력값에 포지셔널 인코딩이 적용된다. masked patch는 제외하고 인코더로 전달하는데 이 덕분에 encoder의 연산량이 감소한다. 패..