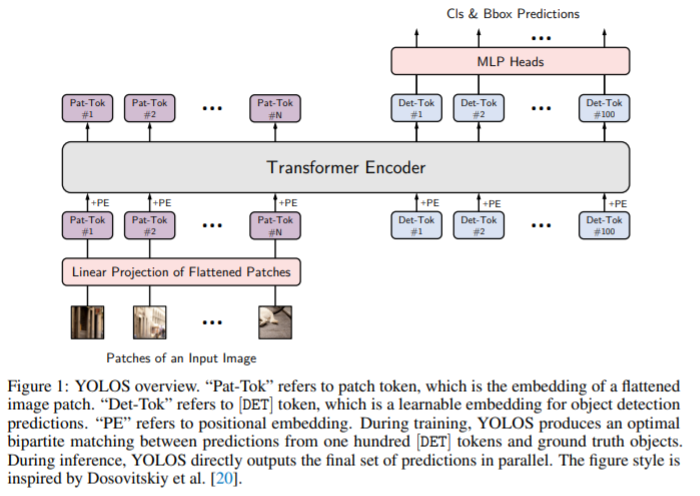
You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection PDF, Object Detection, Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, arXiv 2021 Summary Vision Transformer(ViT)에 class token을 제거하고 Detection token(Det-Tok)을 추가하여 object detection task를 수행합니다. 즉, object detection task를 sequence-to-sequence 방식으로 해결하려 합니다. Dek-Tok는 100xD 차원의 랜덤 초기화 행렬을 사용하며 NxD 차원의 pat..