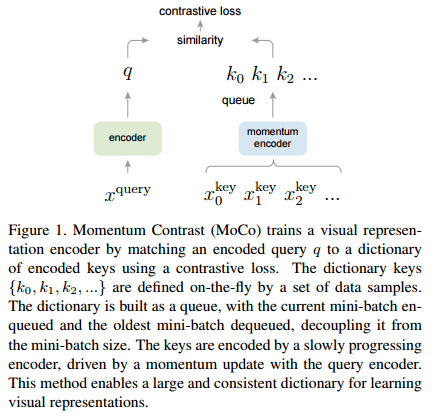
안녕하세요, 오늘 읽은 논문은 MoCo, Momentum Contrast for Unsupervised Visual Representation Learning 입니다. MoCo는 contrastive loss를 사용하는 self-supervised model 입니다. MoCo 이전의 contrastive loss mechanism은 end-to-end, memory bank 방식이 존재했습니다. Contrastive loss를 최대한 활용하려면 많은 수의 negative sample가 필요하고 negative sample의 encoder는 query encoder과 consistent 해야 합니다. end-to-end 방법은 mini-batch내에 존재하는 sample들을 negative sample로 ..