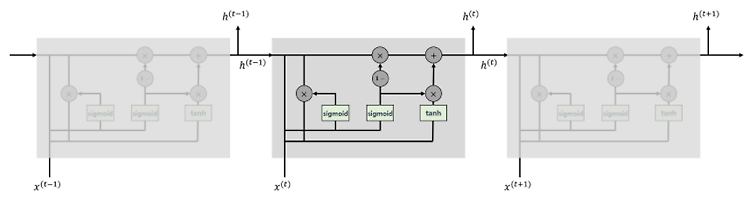
안녕하세요, 오늘 읽은 논문은 Learning Phrase Representation using RNN Encoder-Decoder for Stistical Machine Translation 입니다. 해당 논문에서는 GRU를 제안합니다. 이전 포스팅에서 살펴보았던 Seq2Seq와 이 논문의 차이점은 (1) LSTM 대신에 GRU를 사용합니다. (2) decoder의 각 셀에 context vector와 embedding vector를 추가합니다. 즉 hidden states 정보뿐만 아니라 embedding, context 정보까지 활용합니다. GRU(Gated Recurrent Units) GRU는 LSTM에서 영감을 받아 탄생한 구조입니다. LSTM보다 단순한 구조를 갖고 있으며, cell을 사용하..