사이토고키의 <밑바닥부터 시작하는 딥러닝>을 공부하고 정리해보았습니다.
[딥러닝] 1. 가중치의 초깃값 - 초깃값을 0으로 하면?
사이토고키의 <밑바닥부터 시작하는 딥러닝>을 공부하고 정리해보았습니다. 가중치의 초깃값 신경망 학습에서 특히 중요한 것이 가중치의 초깃값입니다. 가중치의 초깃값을 무엇으로 설정��
deep-learning-study.tistory.com
이전 포스팅에서 역전파 때 가중치가 똑같이 갱신되는 것을 방지하려면 가중치가 고르게 되어버리는 상황을 막아야 한다는 것을 배웠습니다.
가중치의 초깃값에 따라 은닉층의 활성화값 분포 변화
은닉층의 활성화값의 분포를 관찰하면 중요한 정보를 배웠습니다.
가중치의 초깃값에 따라 은닉층 활성화값들이 어떻게 변화하는지 실험을 해보겠습니다.
활성화 함수로 시그모이드 함수를 사용하는 5층 신경망에 무작위로 생성한 입력 데이터를 흘리며 각 층의 활성화값 분포를 히스트그램으로 확인해보겠습니다.
def sigmoid(x):
return 1 / (1 + np.exp(-1))
x = np.random.randn(1000, 100) # 1000개의 데이터
node_num = 100 # 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5 # 은닉층이 5개
activations = {} # 이 곳에 활성화 결과(활성화값)를 저장
fro i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z
층이 5개가 있으며, 각 층의 뉴런은 100개씩입니다.
입력 데이터로서 1000개의 데이터를 정규분포로 무작위로 생성하여 이 5층 신경망에 흘립니다.
활성화 함수로는 시그모이드 함수를 이용했고, 각 층의 활성화 결과를 activations 변수에 저장합니다.
이 코드에서는 가중치의 분포에 주의해야 합니다.
코드에서는 표준편차가 1인 정규분포를 이용했는데, 이 분포된 정도(표준 편차)를 바꿔가며 활성화값들의 분포가 어떻게 변화하는지 관찰하는 것이 이 실험의 목적입니다.
히스토그램을 확인해 보겠습니다.
# 히스토그램 그리기
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + '-layer')
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()
가중치의 표준편차 1
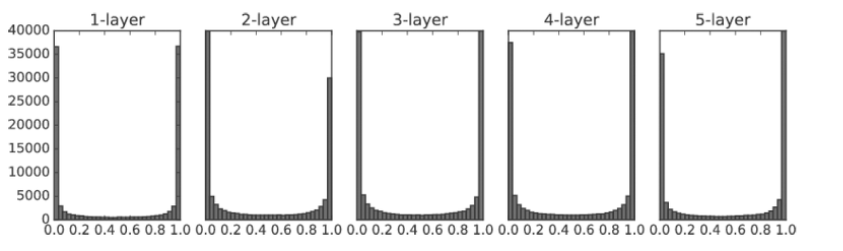
각 층의 활성화 값들이 0과 1에 치우쳐 분포되어 있습니다.
여기에서 사용한 시그모이드 함수는 그 출력이 0에 가까워지자(또는 1에 가까워지자) 그 미분은 0에 다가갑니다.
그래서 데이터가 0과 1에 치우쳐 분포하게 되면 역전파의 기울기 값이 점점 작아지다가 사라집니다.
이것이 기울기 소실(gradient vanishing) 문제입니다.
가중치의 표준편차 0.01
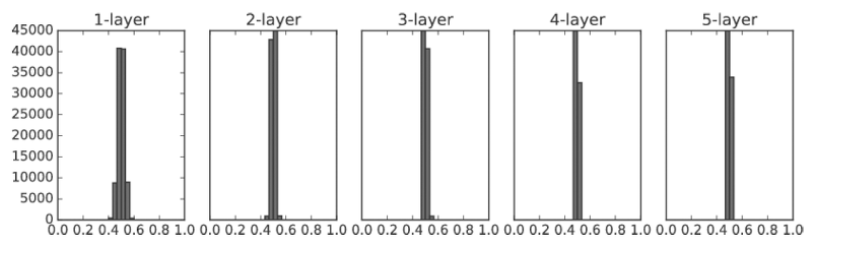
이번에는 0.5 부근에 집중되었습니다.
0과 1로 치우치진 않았으니 기울기 소실 문제는 일어나지 않습니다.
하지만 활성화 값들이 치우쳤다는 것은 큰 문제가 있습니다.
다수의 뉴런이 거의 같은 값을 출력하고 있으니 뉴런을 여러 개 둔 의미가 없어진다는 뜻입니다.
예를 들어 뉴런 100개가 거의 같은 값을 출력한다며 뉴러 1개짜리와 별바 다를 게 없는 것 입니다.
그래서 활성화값들이 치우치며 표현력을 제한한다는 관점에서 문제가 됩니다.
각 층의 활성화값은 적당히 고루 분포되어야 합니다.
층과 층 사이에 적당하게 다양한 데이터가 흐르게 해야 시경망 학습이 효율적으로 이뤄지기 때문입니다.
반대로 치우친 데이터가 흐르면 기울기 소실이나 표현력 제한 문제에 빠져서 학습이 잘 이뤄지지 안흔 경우가 생깁니다.
Xavier 초깃값 사용
현재 Xavier 초깃값은 일반적인 딥러닝 프레임워크들이 표준적으로 이용하고 있습니다.
이 논문에은 앞 계층의 노드가 n개라면 표준편차가 $\frac{1}{n}$인 분포를 사용하면 된다는 결론을 이끌었습니다.
Xavier 초깃값을 사용하면 앞 층에 노드가 많을수록 대상 노드의 초깃값으로 설정하는 가중치가 좁게 퍼집니다.
분포를 확인해보겠습니다.
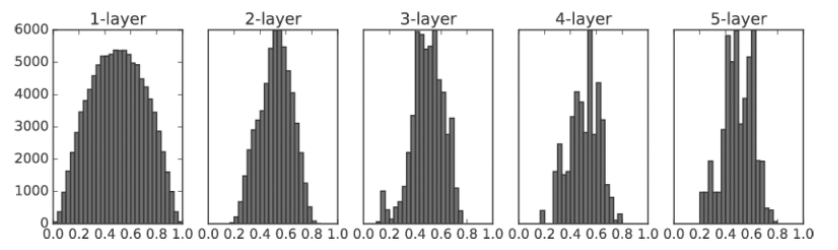
확실히 넓게 분포됨을 알 수 있습니다.
각 층에 흐르는 데이터는 적당히 퍼져 있으므로, 시그모이드 함수의 표현력도 제한받지 않고 학습이 효율적으로 이뤄질 것으로 기대됩니다.
위 그림은 오른쪽으로 갈수록 약간씩 일그러지고 있습니다.
이 일그러짐으 sigmoid 함수 대신 tanh 함수(쌍곡선 함수)를 이용하면 개선됩니다. 실제로 tanh 함수를 이용하면 말끔한 종 모양으로 분포됩니다.
tanh함수도 sigmoid 함수와 같은 'S'자 모양 곡선 함수입니다.
다만 tanh 함수가 원점(0,0)에서 대칭인 S곡선인 반면, sigmoid 함수는 (x, y) = (0, 0.5)에서 대칭인 S 곡선입니다.
활성화 함수용으로는 원점에서 대칭인 함수가 바람직하다고 알려져 있습니다.
Xavier 초깃값은 활성화 함수가 선형인 것을 전제로 이끈 결과입니다.
sigmoid 함수와 tanh 함수는 좌우 대칭이라 중앙 부근이 선형인 함수로 볼 수 있습니다.
그래서 Xavier 초깃값이 적당합니다.
'수학 > 딥러닝 이론' 카테고리의 다른 글
| [딥러닝] 배치 정규화의 알고리즘과 효과 (0) | 2020.10.03 |
|---|---|
| [딥러닝] 3. 가중치의 초깃값 - ReLU를 사용할 때의 가중치 초깃값 - He 초깃값 (0) | 2020.10.03 |
| [딥러닝] 1. 가중치의 초깃값 - 초깃값을 0으로 하면? (0) | 2020.10.02 |
| [딥러닝] 매개변수 갱신 - Adam, 어느 갱신 방법을 이용할 것인가? (0) | 2020.10.02 |
| [딥러닝] 매개변수 갱신 - AdaGrad 기법 (0) | 2020.10.02 |