이번에 읽어볼 논문은 ResNet, 'Deep Residual Learning for Image Recognition' 입니다.
ResNet은 residual repesentation 함수를 학습함으로써 신경망이 152 layer까지 가질 수 있습니다. ResNet은 이전 layer의 입력을 다음 layer로 전달하기 위해 skip connection(또는 shorcut connection)을 사용합니다. 이 skip connection은 깊은 신경망이 가능하게 하고 ResNet은 ILSVRC 2015 우승을 했습니다.
Plain Network의 문제점
Plain network는 skip/shortcut connection을 사용하지 않은 일반적인 CNN(AlexNet, VGGNet) 신경망을 의미합니다. plaing network가 점점 깊어질 수록 기울기(gradient) 소실(vanishing)과 폭발(exploding) 문제가 발생합니다.
기울기 소실과 폭발
기울기를 구하기 위해 가중치에 해당하는 손실 함수의 미분을 오차역전파법으로 구합니다. 이 과정에서 활성화 함수의 편미분을 구하고 그 값을 곱해줍니다. 이는 layer가 뒷단으로 갈수록 활성화함수의 미분값이 점점 작아지거나 커지는 효과를 갖습니다.
신경망이 깊을 때, 작은 미분값이 여러번 곱해지면 0에 가까워 질 것입니다. 이를 기울기 소실이라고 합니다.
반대로, 큰 미분값이 여러번 곱해지면 값이 매우 커질 것입니다. 이를 기울기 폭발이라고 합니다.
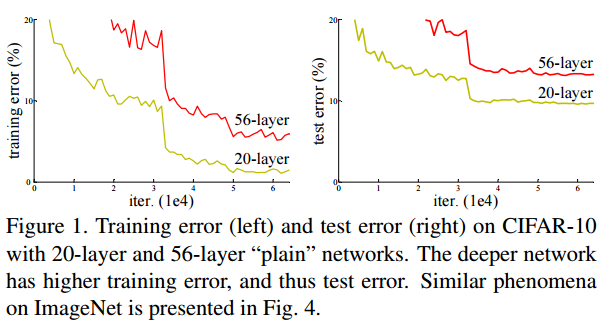
신경망이 깊어질 수록 더 정확한 예측을 할 것이라고 생각할 수 있습니다. 하지만 아래 그림은 20-layer plain network가 50-layer plain network보다 더 낮은 train error와 test error를 얻은 것을 보여줍니다. 논문에서는 이를 degradation 문제라고 말하고 기울기 소실에의해 발생한다고 합니다.
Skip / Shortcut Connection in Residual Network(ResNet)
기울기 소실/폭발 문제를 해결하기 위해, 입력 x를 몇 layer 이후의 출력값에 더해주는 skip/shortcut connection을 더해줍니다.
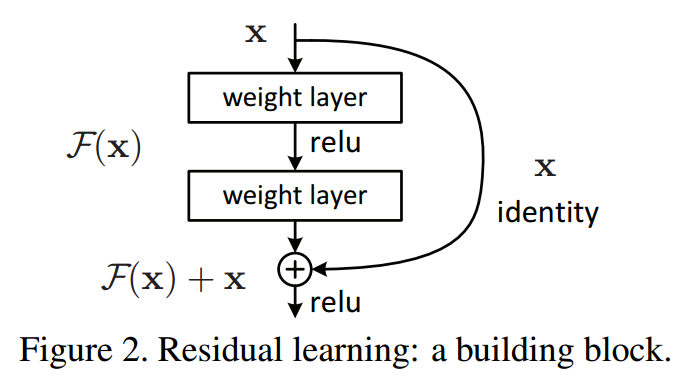
기존의 신경망은 H(x) = x가 되도록 학습 했습니다. skip connection에 의해 출력값에 x를 더하고 H(x) = F(x) + x로 정의합니다. 그리고 F(x) = 0이 되도록 학습하여 H(x) = 0 + x가 되도록 합니다. 이 방법이 최적화하기 훨씬 쉽다고 합니다. 미분을 했을 때 더해진 x가 1이 되어 기울기 소실 문제가 해결됩니다.
기울기 소실 문제가 해결되면 정확도가 감소되지 않고 신경망의 layer를 깊게 쌓을 수 있어 더 나은 성능의 신경망을 구축할 수 있습니다.
ResNet Architecture
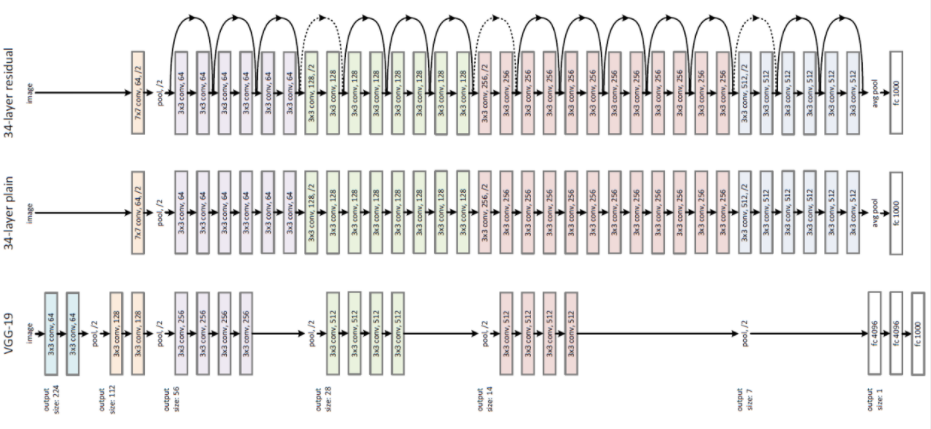
위 그림은 ResNet 구조를 보여줍니다.
맨 아래 구조는 VGG-19 입니다.
중간 구조는 VGG-19가 더 깊어진 34-layer plain network입니다.
맨 위 구조는 34-layer residual network(ResNet)이며 plain network에 skip/short connection이 추가되었습니다.
skip/short connection을 추가하기 위해서는 더해지는 값x와 출력값의 차원이 같아야 합니다. ResNet에서는 입력 차원이 출력 차원보다 작을 때 사용하는 3종류의 skip/shortcut connection이 있습니다.
(A) Shortcut은 증가하는 차원에 대해 추가적으로 zero padding을 적용하여 identity mapping을 수행합니다. 따라서 추가적인 파라미터가 없습니다.
(B) 차원이 증가할 때만 projection shortcut을 사용합니다. 다른 shortcut은 identity입니다. 추가적인 파라미터가 필요합니다.
(C) 모든 shortcut이 projection입니다. B보다 많은 파라미터가 필요합니다.
이 논문에서 C는 사용하지 않았습니다. 모델의 연산량이 증가하기 때문입니다. 아래 소개할 bottleneck 구조에서 A 옵션을 사용합니다.
Bottleneck Design
신경망이 깊어지면 학습하는데 소요되는 시간은 엄청 오래 걸릴 것 입니다. bottleneck design은 다음과 같이 신경망의 복잡도를 감소하기 위해 사용됩니다.

1x1 conv layers는 오른쪽 그림과 같이 신경망의 시작과 끝에 추가됩니다. 이 기법은 NIN과 GoogLeNet에서 제안되었습니다. 1x1 conv는 신경망의 성능을 감소시키지 않고 파라미터 수를 감소시킵니다.
bottleneck design으로 연산량을 감소시켜 34-layer는 50-layer ResNet이 되고, bottleneck design을 지닌 더 깊은 신경망이 있습니다. ResNet-101과 ResNet-152 입니다. 전체적인 구조는 아래와 같습니다.

VGG-16 보다 ResNet-152가 더 적은 연산량을 갖고 있습니다.
Plain Nerwork VS ResNet
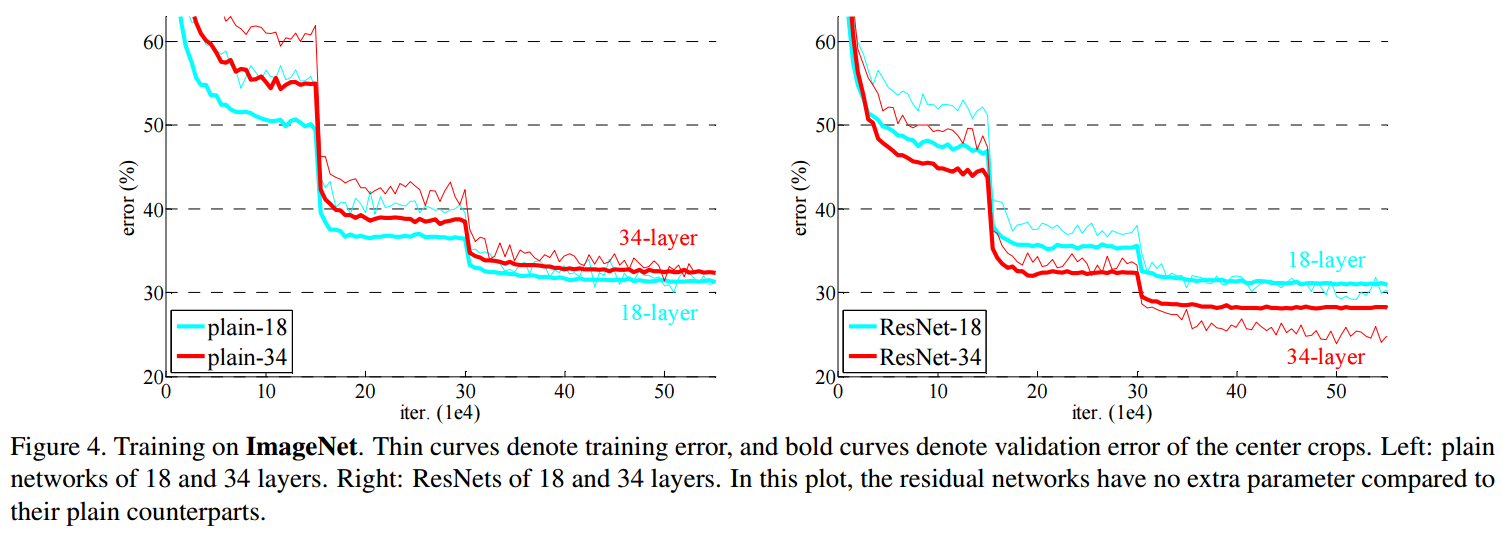
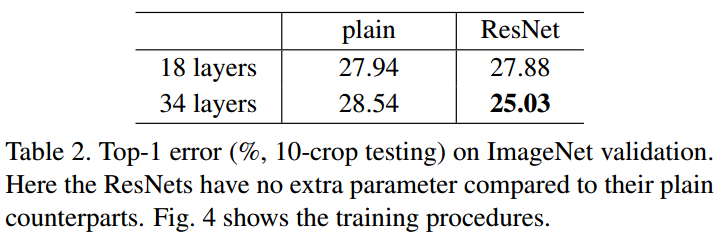
plain network에서 기울기 소실 문제 때문에 18-layer의 성능이 34-layer보다 뛰어납니다.
ResNet에서는 기울기 소실 문제가 skip connection에 의해 해결되어 34-layer의 성능이 18-layer보다 뛰어납니다.
18-layer plain network와 18-layer ResNet network에는 차이점이 없습니다. 얇은 신경망에서는 기울기 소실 문제가 나타나지 않기 때문입니다.
참고자료
'논문 읽기 > Classification' 카테고리의 다른 글
| [논문 읽기] Inception-v3(2015) 리뷰, Rethinking the Inception Architecture for Computer Vision (1) | 2021.03.13 |
|---|---|
| [논문 읽기] Pre-Activation ResNet(2016) 리뷰, Identity Mappings in Deep Residual Networks (0) | 2021.03.11 |
| [논문 리뷰] VGGNet(2014) 리뷰와 파이토치 구현 (4) | 2020.12.31 |
| [논문 리뷰] GoogLeNet (2014) 리뷰와 파이토치 구현 (3) | 2020.12.27 |
| [논문 리뷰] AlexNet(2012) 리뷰와 파이토치 구현 (7) | 2020.12.22 |