이번에 읽어볼 논문은 'YOLOv3: An Incermetal Improvement' 입니다.
YOLOv3은 YOLOv2에서 개선된 버전입니다. 예를 들어, FPN을 사용하여 multi-scale에서 feature을 추출하고, shortcut connection을 활용한 DarkNet-53, class 예측시에 softmax 대신 개별 클래스 별로 logistic regression을 사용합니다. 기본 작동방식은 YOLOv2와 동일하므로 YOLOv2 논문을 읽고, YOLOv3을 살펴보는 것을 추천드립니다.
큰 변화가 일어나지 않았으며, YOLOv2에 최신 기법을 적용하여 성능을 끌어올렸습니다.

YOLov3의 성능입니다. RetinaNet 논문에서 사용한 figure에서 YOLOv3을 추가했습니다. YOLOv3은 그래프를 벗어나 왼쪽에 위치해 있는데, 그만큼 빠르게 작동한다는 것을 의미합니다. 320x320 YOLOv3은 28.2mAP의 정확도로 22ms로 검출을 수행합니다.
1. Bounding Box prediction

YOLOv3에서 bounding box를 예측하는 방법은 YOLOv2와 동일합니다. tx, ty, tw, th가 예측됩니다. 예측된 tx, ty는 시그모이드 함수를 거쳐서 범위가 0~1으로 제한됩니다. 그리고 cx, cy와 더해져 바운딩박스가 됩니다 cx, cy는 객체를 포함하고 있는 grid cell의 좌표입니다. tw, th는 지수승로 사용되어 pw, ph와 곱해집니다. pw, ph는 이전 바운딩박스의 너비와 높이입니다. 이처럼 다양한 정규화 기법으로 바운딩박스가 한번에 업데이트 되는 범위를 제한하여 학습이 안정적으로 되게 합니다.(YOLOv2에 자세한 내용이 나와있습니다.) 학습동안 SSE(sum of squared error loss)를 사용합니다.
objectness score(객체를 포함하면 1, 그렇지 않으면 0)은 logistic regression을 사용하여 예측됩니다. 만약 바운딩박스가 다른 바운딩박스 보다 ground-truth와의 높은 IOU를 지니면 1이 됩니다. 하나의 바운딩박스가 ground truth에 할당됩니다.
2. Class Prediction
각 박스는 바운딩 박스의 class를 예측합니다. softmax를 사용하지 않습니다. 대신에 binary cross-enrtopy loss를 사용한 독립적인 logistic classfier를 사용합니다. 이 방법이 더 복잡한 데이터셋(Open images Dataset)으로 YOLO를 학습하는 데에 도움을 준다고 합니다.
3. Prediction Across Scales
3개의 다른 scale이 사용됩니다. FPN과 같이 특징은 feature pyramid에서 추출됩니다. 3개의 scale이 사용되므로 3개의 pyramid의 level에서 특징을 추출한다는 의미가 됩니다.
Darknet-53에 여러 convolutional layer를 추가합니다. 추가된 convolutional layer은 feature pyramid를 생성하기 위한 용도로 이용됩니다.(upsampling). 최종 feature map에 upsampling을 2번 합니다. 3개의 scale을 사용하므로, 최종 feature map과 이전 2개의 feature map은 upsampled된 feature map과 통합합니다. FPN과 유사한 방식으로 더 풍부한 정보를 활용합니다.
COCO dataset에 대하여 각 scale에서 3개의 박스를 사용합니다. 출력값은 NxNx[3x(4+1+80)]이 됩니다. 4는 바운딩박스 offset, 1은 objectness prediction, 80은 class prediction 입니다. N은 grid의 크기입니다.
anchor 박스를 생성할 때 k-means clusterung을 사용합니다. 3개의 scale에서 3개의 box를 사용하므로 9개의 anchor 박스가 필요합니다. COCO dataset에 k-means clustering을 적용했을 때, (10x13), (16x30), (33x23), (30x61), (62x45), (59x119), (116x90), (156x198), (373x326) 박스가 생성되었습니다.
4. Feature Extractor
YOLOv3은 backbone network로 DarkNet-53을 사용합니다. DarkNet-53은 53개의 convolutional layer로 이루어져 있고, ResNet에서 제안된 shortcut connection을 사용합니다.

ImageNet dataset에서의 Darknet-53의 성능입니다.

ResNet-101과 비교했을 때, Darknet-53이 더 나은 성능을 보입니다. 약 1.5배 더 빠릅니다.
Result
YOLOv3의 성능입니다.

YOLOv3은 mAP@0.5로 평가했을 때 성능이 월등히 좋습니다.

overall mAP으로 YOLOv3을 평가하면 성능이 상당히 떨어집니다.
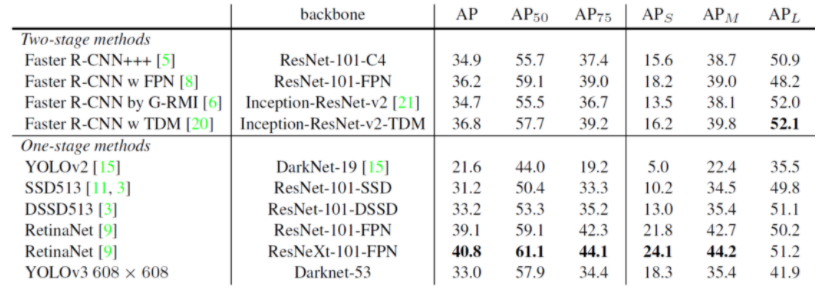
테이블로 정리된 성능입니다.
참고자료
[2] towardsdatascience.com/review-yolov3-you-only-look-once-object-detection-eab75d7a1ba6