이번에 읽어볼 논문은 R-FCN, Object Detection via Region-based Fully Convolutional Networks 입니다.
R-FCN은 position-sensitive score map를 제안합니다. 이 position-sensitive score map은 classification에서의 translation-invariance와 object detection에서의 translation-variance 사이의 딜레마를 해결하기 위해 제안되었습니다.
translation-invariance vs translation-variance
Classification에서는 translation-invariance가 중요합니다. 이미지 내에서 물체의 위치와 관계없이 class만을 예측하면 되기 때문입니다. 반면에 Object Detection에서는 객체의 위치까지 예측을 해야하므로, translation-variance가 어느 정도 필요합니다. 객체가 이동하면 바운딩 박스와의 IOU가 변경되기 때문입니다.
일반적으로 Classification 모델은 마지막 pooling layer 이후에 fc layer로 구성됩니다. object detection은 translation-variance를 얻기 위해 pooling layer를 ROI pooling layer로 변경했습니다. 하지만, Classification에서의 높은 정확도에 비하여 object detection에서의 정확도는 낮았습니다. 이 문제를 해결하기 위해 ResNet 저자는 RoI pooling layer를 convolutional layer 사이에 위치시켰습니다. 이 방법은 정확도가 어느정도 향상되었지만, training과 test efficiency는 감소했습니다.
R-FCN은 semantic segmentation 에서 제안된 FCN을 backbone으로 사용합니다. 그리고 translation variance를 얻기 위해, 여러 convolutional layer를 사용하여 position-sentive score maps를 생성합니다. 각 score map은 공간 정보(예를 들어, 객체의 좌측 상단 등)를 담게 됩니다. 여기에 RoI pooling layer를 추가하여 score map의 정보를 활용합니다.
R-FCN의 핵심 아이디어를 시각화한 그림입니다.
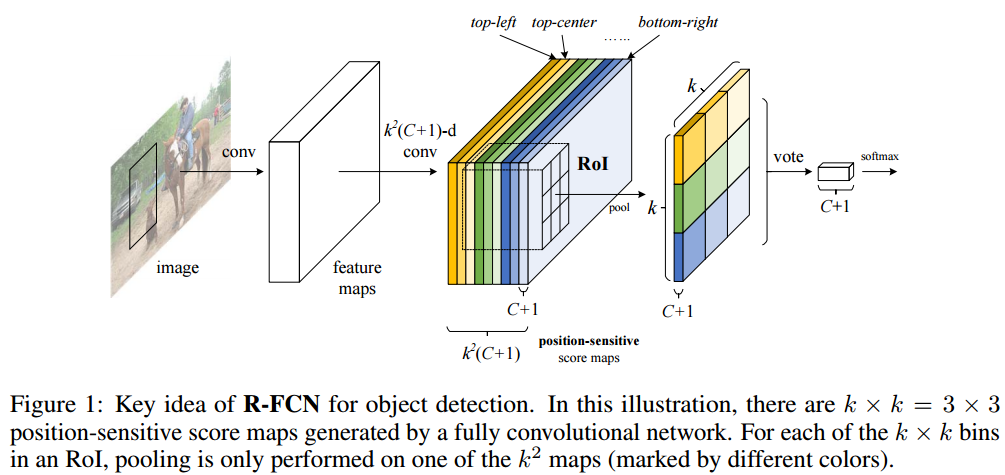
R-FCN

R-FCN은 2stage object detection 입니다. 위 그림을 보면 conv layer의 마지막 feature map에서 두 갈래로 나뉩니다. 하나는 RPN이 region proposals를 생성하고, 다른 하나는 conv layer를 거쳐서 position-sensitive score map을 생성합니다. 그리고 이 map에 RPN이 생성한 region proposals가 projection 됩니다.

position-sensitive score map은 k x k x (Class + 1) 채널을 갖습니다.(왜 kxkx(class+1) 채널을 갖도록 설계했는지 이해가 잘 안가네요..) 논문에서는 k를 3으로 설정하여 객체의 좌측 상단, 중앙 상단, 우측 상단, 좌측 중단, 중앙 중단, 등등 정보를 encode 합니다. 참고로 여기서 k는 grid size가 아니라, RoI를 분할하는 숫자입니다. 예를 들어, RoI가 hxw의 크기를 갖고 있으면 h/k x w/k로 분할합니다.

그리고 position-sensitive score map에 투사된 모든 RoI에 RoI pooling layer를 적용하여 kxk 크기의 C+1채널 feature map을 생성합니다. 이 feature map에 vote(average pooling)을 적용하여, (C+1) 채널의 flatten vector로 변환합니다. 그리고나서 softmax를 거쳐 class를 예측합니다. bounding box 좌표는 feature map에 4 x k x k 차원의 position sensitive score map을 생성하고, 동일한 과정을 거쳐서 생성합니다. 즉, position-sensitive score map을 두 개 생성하는 것입니다.

position sensitive score map의 작동 원리입니다. 위 그림에서 Figure3은 position-sensitive score map에서 전체적으로 높은 값을 나타내고 있습니다. 이 값이 voting과 soft max를 거쳐서 person이라고 판별합니다. 반면에 RoI가 객체를 정확하게 포착하지 않으면, position sensitive score map이 전체적으로 낮은 값을 갖게 됩니다.
Performance
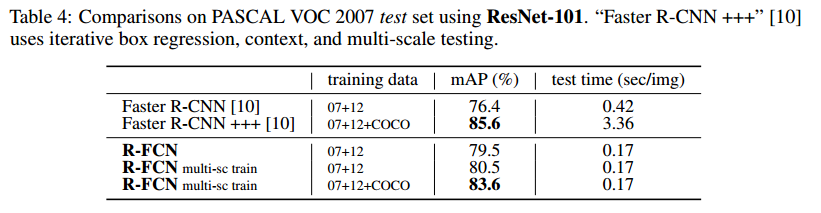

참고자료
'논문 읽기 > Object Detection' 카테고리의 다른 글
| [논문 읽기] DCN(2017) 리뷰, Deformable Convolution Networks (0) | 2021.04.13 |
|---|---|
| [논문 읽기] RON(2017) 리뷰, Reverse Connection with Objectness Prior Networks for Object Detection (0) | 2021.04.09 |
| [논문 읽기] DSSD(2017) 리뷰, Deconvolutional Single Shot Detector (2) | 2021.04.03 |
| [논문 읽기] YOLOv3(2018) 리뷰 (2) | 2021.03.10 |
| [논문 읽기] RetinaNet(2017) 리뷰, Focal Loss for Dense Object Detection (0) | 2021.03.08 |