안녕하세요, 오늘 읽은 논문은 Distilling the Knoeledge in a Neural Network 입니다.
해당 논문은 Knowledge Distillation을 제안합니다. Knowledge Distillation은 teacher model이 갖고 있는 지식을 더 작은 모델인 student model에 transfer 하는 것을 의미합니다.
사이즈가 큰 teacher model이 갖고 있는 지식을 사이즈가 작은 student model에 지식을 transfer한다면, model compression의 효과가 있습니다. 즉, 실제 모델을 배포할 때, 더 작은 모델을 사용하여 예측 속도도 높이고, 정확도도 높일 수 있습니다. 이 외에도 knowledge distillation은 model을 generalization 하는 효과도 있어, test error를 낮출 수 있습니다.
실제로 2020년에 efficientnet을 기반으로 knowledge distillation하는 Noisy Student와 Meta Pseudo label은 classification 분야에서 Sota를 달성합니다.
해당 논문에서 MNIST dataset에서 숫자 3 데이터를 제거하여 student model을 knowledge distillation 방법으로 학습시킵니다. 숫자 3에 대한 정보를 학습하지 않았지만, soft label이 갖고 있는 정보로만 학습하여 test 3 이미지에 대해 98.6%의 정확도를 달성합니다.
또한 student model이 10개의 모델을 ensemble한 model과 비슷한 정확도를 보여줍니다. 10개의 모델을 ensemble하는 비용을 생각하면, knowledge distillation은 정말 효과적인 방법입니다.

Soft Label

knowledge distillation은 Soft label 방식을 사용하여 지식을 증류합니다. 사전에 학습된 teacher model로부터 soft label을 출력합니다. soft label은 정답일 확률이 [0.1, 0.2, 0.3, 0.05] 처럼 극단적인 값을 갖지 않습니다. 정답 이외의 확률이 존재하여 해당 이미지에서 더 많은 정보를 추출합니다. 더 많은 정보를 갖고 있는 soft label을 사용하여 student model을 학습합니다.
반면에, hard label은 [0,0,1,0] 처럼 정답일 확률이 극단적인 값을 갖는 label 입니다. 정답이외에 다른 정보를 포함하지 않습니다.
위 식에서 T는 temparature을 의미합니다. T가 높으면 soft label을 출력하고, T=1이면 hard label을 출력합니다.
Knowledge Distillation Loss

첫 번째 항은 teacher model에서 Soft Label을 계산하고, 이 Soft label과 동일한 결과값을 출력하도록 student model을 학습합니다. T는 soft label을 계산할 때 사용하는 temparature 입니다.
두 번째 항은 student model의 출력값과 hard label 사이의 crossentropy label을 계산합니다.
알파는 두 항 사이의 비율을 조절합니다.
파이토치로는 다음과 같이 구현할 수 있습니다.
# knowledge distillation loss
def distillation(y, labels, teacher_scores, T, alpha):
# distillation loss + classification loss
# y: student
# labels: hard label
# teacher_scores: soft label
return nn.KLDivLoss()(F.log_softmax(y/T), F.softmax(teacher_scores/T)) * (T*T * 2.0 + alpha) + F.cross_entropy(y,labels) * (1.-alpha)
학습 방법
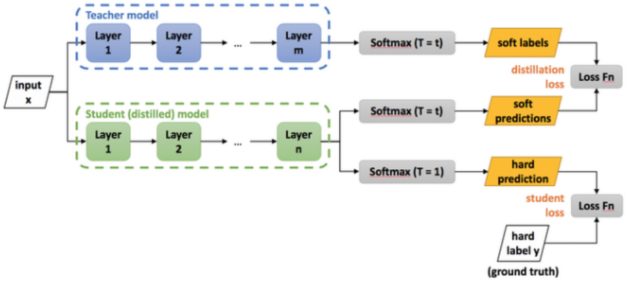
1) teacher model을 학습합니다.
2) teacher model 로부터 soft label을 추출하여 knowledge distillation loss로 student model을 학습니다.
PyTorch로 Knowledge distillation을 구현하여 MNIST dataset으로 학습해보는 과정을 아래 포스팅에 담아보았습니다 ㅎㅎ
[논문 구현] PyTorch로 Knowledge Distillation(2014) 구현하기
안녕하세요, 이번 포스팅에서는 PyTorch로 Knowledge Distillation을 구현해보도록 하겠습니다. 작업 환경은 Google Colab에서 진행했습니다. 논문 리뷰는 아래 포스팅에서 확인하실 수 있습니다. [논문
deep-learning-study.tistory.com
참고자료
[1] https://github.com/peterliht/knowledge-distillation-pytorch
[3] http://cs230.stanford.edu/files_winter_2018/projects/6940224.pdf