안녕하세요, 오늘 읽은 논문은 A Simple Framework for Contrastive Learning of Visual Representations 입니다.
해당 논문은 self supervised learning에서 major component를 연구합니다. 그리고 이 component를 결합하여 sota 성능을 달성합니다.
논문에서 설명하는 major component는 다음과 같습니다.
(1) data augmentation
contrastive learning은 batch내에 이미지를 추출하여 2개의 transformation을 적용해 각각 query와 key를 생성합니다. 동일한 image에 적용된 transformation은 similar이고, 나머지 batch에 존재하는 다르 이미지에 transformaton을 적용한 이미지는 dissimilar가 됩니다. 이처럼 augmentation을 적용하는데, 어떤 augmentation이 효과적인지 실험을 합니다.
unsupervised contrastive learning은 supervised learning보다 강한 data augmentation에 이득을 얻습니다. 또한 SL에서 사용하는 data augmentation이 SSL에서 효과가 적고 SSL에서 효과가 좋은 augmentation은 SL에서 효과가 적습니다.
해당 논문에서 SSL은 random crop and resize, color distortion, blur 가 결합된 augmentation이 좋다고 설명합니다.

위처럼 10개의 augmentation에서 2개의 augmentation을 결합해 brute force 실험을 합니다.

crop + color 가 성능이 가장 좋습니다.

동일한 이미지 내에서 random crop을 한 경우에 crop된 이미지는 동일한 color distribution을 갖습니다. 따라서 모델은 color histogram 정보를 사용하여 구별을 할 수 있는데, 이를 방지하기 위해 color distortion을 적용합니다.

위 표는 SL과 SSL에서 성능이 좋은 augmentation이 다르다는 것을 보여줍니다. SL에서 자주 사용하는 AutoAug는 SSL에서 성능이 좋지 않습니다.
(2) Learnable nonlinear transformation

encoder가 representation을 생성하고, 이 representation에 non linear head를 사용하면 성능이 더 좋아집니다. 논문은 MLP + ReLU + MLP 구조의 non linear head를 사용합니다. 저자는 nonlinear projection이 중요한 이유는 contrastive loss에 의해 유발되는 정보 손실 때문이라고 설명합니다.

특히, z=g(h) 는 data transformation에 불변하도록 학습됩니다. h는 encoder의 출력값인 representation이고, g()는 non linear head 입니다. 따라서 g는 객체의 color 또는 방향같은 downstream task에 유용한 정보를 제거합니다. nonlinear transformation g()를 활용함으로써 더 많은 정보가 h에 형성되고 유지됩니다.

위 표는 g(h)는 정보가 손실되고, h는 적용된 transformation에 대해 더 많은 정보를 포함하고 있다는 것을 보여줍니다.
따라서 학습시에는 g()를 사용하고, 학습이 끝나면 g()를 버립니다.
(3) Normalized cross entropy loss with adjustable temperature
논문은 아래와 같은 loss function을 사용하고 이를 NT-Xent loss(normalized temperature-scaled cross entropy loss)라고 부릅니다. 그리고 NT-Xent loss를 다른 loss들과 비교하는 실험을 합니다. 또한 normalized embedding와 적절한 temperature를 적용한 contrastive cross entropy loss의 효과를 실험으로 보여줍니다.

저자는 temperature을 적절하게 사용하는 것이 hard negatives로부터 모델을 학습시키는데에 도움을 준다고 설명합니다.

위 표에서 gradient를 살펴보면 NT-Xent는 positive 와 negative example 각각에 서로 다른 weight를 가하고 있습니다. 이 덕분에 hard negative mining 효과가 있습니다.

위 표는 loss function에 따른 성능 비교입니다.
loss function에서 temperature은 batch size에 따라 효과가 다릅니다.

(4) large batch size and longer traning
contrastive learning에서 중요한 것은 negative sample의 수 입니다. large batch와 longer training을 한다면 많은 negative sample을 사용할 수 있습니다.
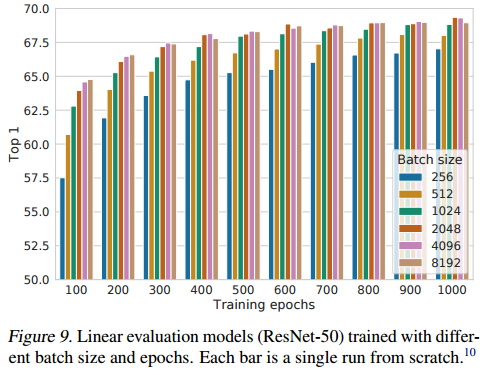
위 그림을 보면 batch size와 epoch가 커질수록 높은 정확도를 나타냅니다.
Method
위 4가지 요소를 결합한 SimCLR의 방법입니다.
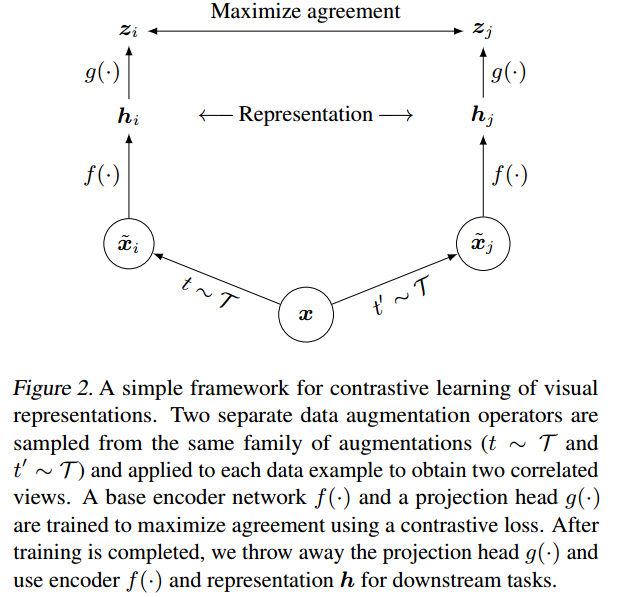

하나의 이미지에 2개의 transformation을 적용합니다. 만약 8192 batch size를 사용한다면 한 배치내에 16382의 negative sample이 존재합니다. 2개은 positive pair 입니다. batch size가 너무 커도 학습이 unstable 하므로 LARS optimizer와 Global BN을 사용합니다.
Experiment
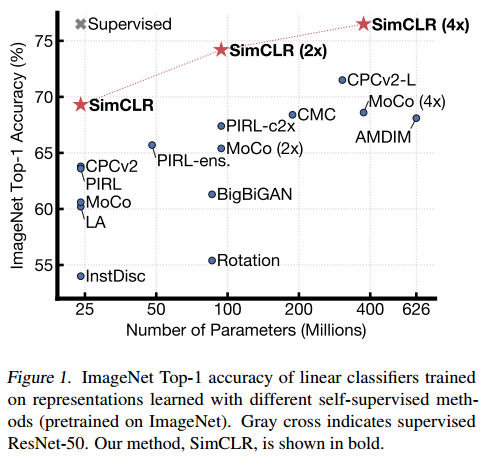
다른 기법들과의 비교입니다.


transfer learning 결과입니다.

참고 자료