Deformable DETR: Deformable Transformers for End-to-End Object Detection
PDF, Object Detection, Xizhou Zhu, Weije Su, Lewei Lu, Xiaogang Wang, Jifeng Dai, arXiv 2020
Summary
DETR의 문제점을 개선한 Deformable DETR 입니다.
DETR은 (1) 수렴속도가 느리고 (2) 작은 물체에 대해서 낮은 성능을 갖습니다.
수렴속도가 느린 이유는 학습 초기에 attention weight이 모든 픽셀에 대하여 평균값을 갖고 학습이 진행되면서 attention map은 sparse값을 갖습니다. 이 과정에서 어려움을 겪기 때문입니다.
작은 물체에 대해서 낮은 성능을 갖는 이유는 다양한 scale의 feature map을 활용하지 않습니다. CNN의 여러 feature map의 정보를 활용하는 FPN 구조를 사용한다면 작은 객체에 대한 성능을 높일 수 있습니다.
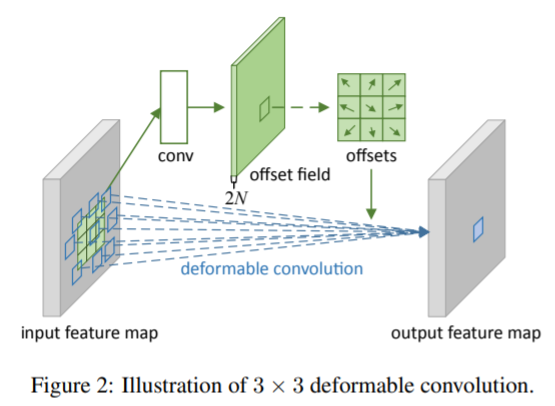
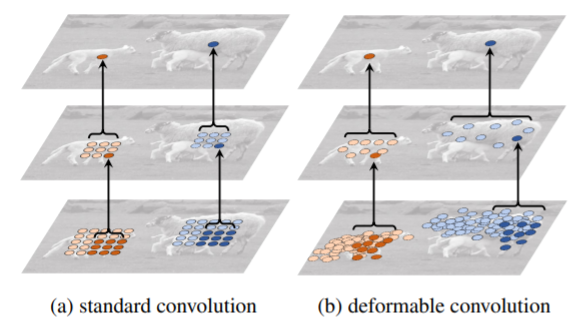
Deformable DETR은 DCN으로부터 아이디어를 얻었습니다.
DCN을 잠깐 설명하자면 convolution filter의 kernel 위치를 학습시켜 광범위한 receptive field를 갖게 하는 것이었습니다. 기준이 되는 픽셀에 대하여 offset을 FC layer로 학습시켜 해당 offset에 대해서 conv 연산을 수행합니다. 기준 픽셀과 연관되어 있는 offset 픽셀을 학습하여 큰 객체의 경우에 큰 offset이 학습되고, 작은 객체에 대하여 작은 offset이 학습됩니다.
DCN에서 사용하는 deformable conv를 사용하는 것은 아니고 이 아이디어만 가져와 attention에 적용합니다.

DCN에서는 conv filter의 offset을 학습했다면 deformable DETR은 encoder내 attention의 입력이 되는 key를 offset으로 사용합니다. key가 offset point가 되는 데, 논문에서는 offset point의 수를 4로 사용합니다. key의 요소가 감소하므로 모델의 연산량이 감소됩니다.

offset point를 어떻게 sample 할까요??
학습가능한 query feature $z_q$에 linear를 적용해 학습가능한 파라미터로 offset point를 정의합니다.
학습된 offset은 attention의 key, value가 되어 attention 연산을 수행합니다.


해당 논문에서 DETR의 작은 객체에 대한 낮은 성능을 개선하기 위해 backbone의 다양한 feature map을 활용할 수 있는 multi-scale deformable attention module을 제안합니다.

여기까지 Deformable DETR 구조에 대한 설명이었습니다.
저자는 성능 향상을 위해 두 가지 방법 (1) Iterative Bounding Box Refinement, (2) Two-Stage Deformable DETR을 추가로 사용합니다.
Experiment

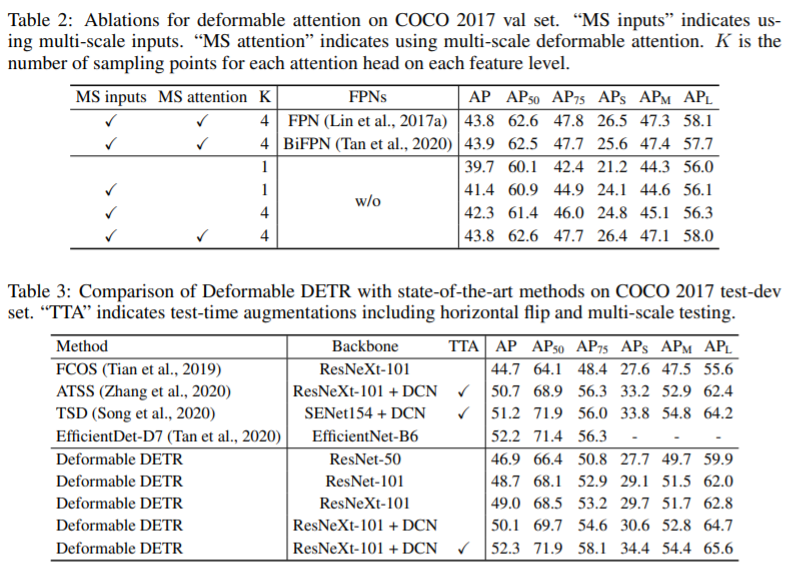
What I like about the paper
- DETR의 문제점을 잘 해결합니다.
my github
Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch
공부 목적으로 논문을 리뷰하고 해당 논문 파이토치 재구현을 합니다. Contribute to Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch development by creating an account on GitHub.
github.com