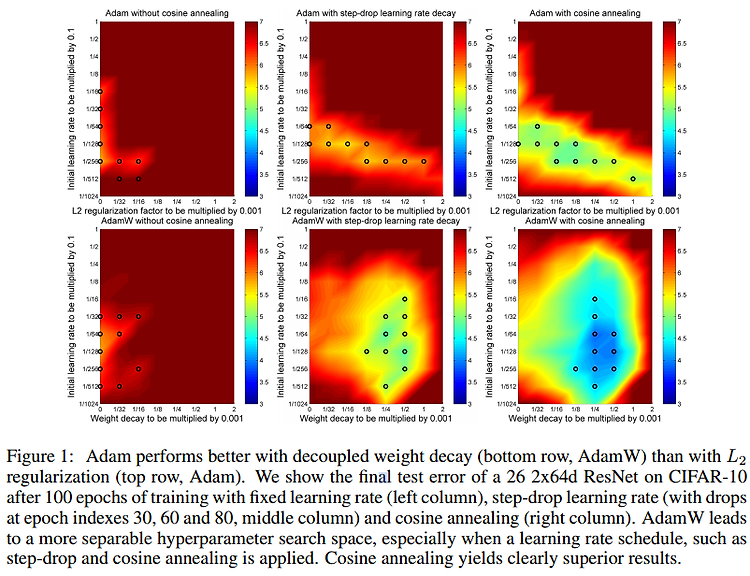
안녕하세요, 오늘 읽은 논문은 AdamW(2017), Decoupled Weight Decay Regularization 입니다. 핵심 정리 weight decay는 loss function에 L2 regularization를 추가하여 구현할 수 있으며 딥러닝 라이브러리가 optimization 함수에 동일한 방법으로 적용되어 있습니다. SGD의 경우에는 weight decay = L2 reg 가 성립하지만 Adam의 경우에 파라미터마다 학습률을 다르게 적용하여 L2 reg로 weight decay를 구현한다면 동일하지 않아 성능이 하락합니다. 이 문제를 해결하기 위해 weight decay를 분리하여 따로 구현합니다. Motivation 여러 task에 test를 진행할때, SGD with moment..