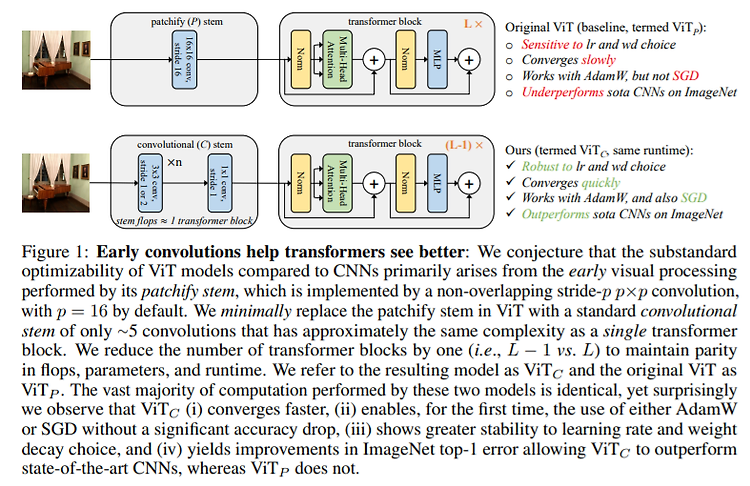
Early Convolutions Help Transformers See Better Tate Xiao, Mannat Singh, Eric Mintum, Trevor Darrell, Piotr Dollar, Ross Girschick, arXiv 2021 PDF, Vision Transformer By SeonghoonYu August 9th, 2021 Summary ViT는 Optimization에 민감합니다. 느린 수렴속도, Optimizer SGD를 사용하면 수렴이 안되고 lr 또는 weight decay 계수에도 민감합니다. 또한 ImageNet 에서 CNN의 성능을 뛰어넘지 못합니다. 저자는 ViT가 Optimization에 민감한 이유가 ViT의 초기 image를 patch 단위로 자를 때 사..