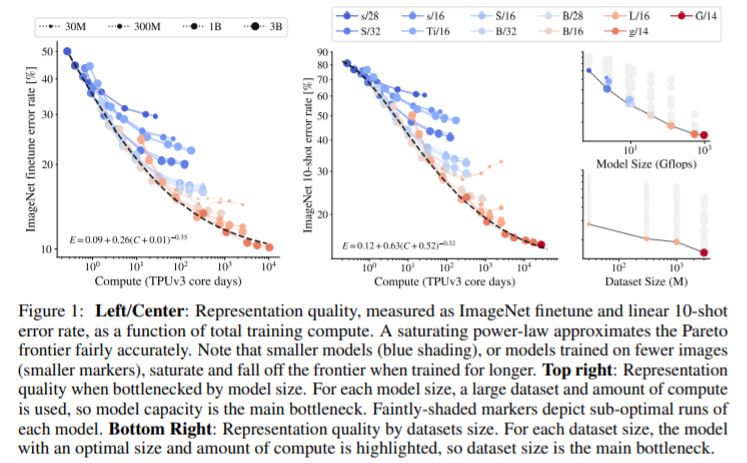
Scaling Vision Transformers PDF, Vision Transformer, Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, Lucas Beyer arXiv 2021 Summary 2 bilion 파라미터를 가진 ViT-G 모델을 학습하여 90.45% SOTA 성능을 달성합니다. 논문에서 여러가지 실험 결과를 보여줍니다. 인상 깊었던 몇 가지를 살펴보겠습니다. 모델 size와 data size 사이의 관계를 실험합니다. 이는 직관과 동일한 실험 결과를 도출합니다. model size와 data size이 클수록 좋은 성능을 달성합니다. downstream task에 trasnfer learning을 진행할 때, ViT에서 예측을 수행하는 head..