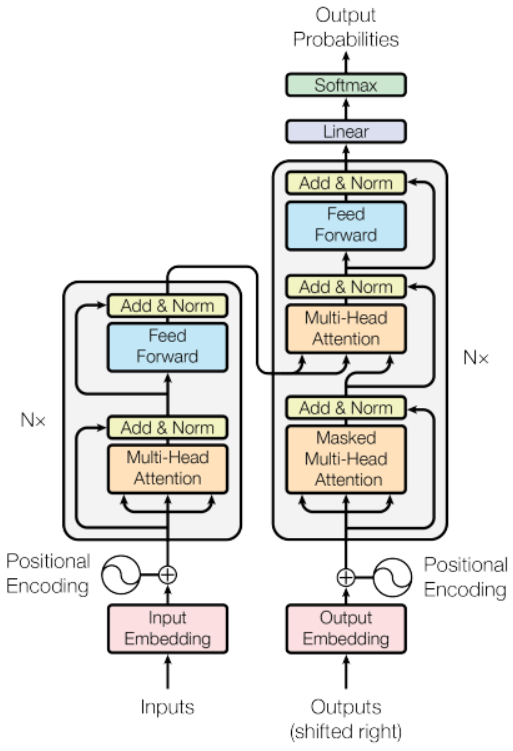
안녕하세요, 오늘 읽은 논문은 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 입니다. 해당 논문은 transformer를 image patch의 sequence에 적용하여 classification을 수행합니다. transformer는 computational efficiency와 scalability한 속성을 갖고 있어 엄청난 크기의 파라미터를 가진 모델로 확장할 수 있습니다. 컴퓨터 비전에서도 이 transformer을 적용하여 VIT는 엄청난 크기의 데이터셋으로 학습하여 SOTA를 달성합니다. transformer를 computer vision에서 적용하기에 inductive bias를 갖고 있습니다. CNN은 ..