(밑바닥부터 시작하는 딥러닝, 사이토고키) 를 바탕으로 작성하였습니다.
신경망 학습 (1) - 손실 함수와 수치 미분
이번 포스팅의 주제는 신경망 학습입니다. 여기서 학습이란 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것을 뜻합니다.
- 손실 함수를 소개합니다. 손실 함수는 신경망이 학습할 수 있도록 해주는 지표입니다. 이 손실 함수의 결과값을 가장 작게 만드는 가중치 매개변수를 찾는 것이 학습의 목표입니다.
- 경사법을 소개합니다. 손실 함수의 값을 가급적 작게 만드는 기법으로, 함수의 기울기를 활용합니다.
1. 데이터에서 학습한다.
신경망의 특징은 데이터를 보고 학습할 수 있다는 점입니다. 데이터에서 학습한다는 것은 가중치 매개변수의 값을 데이터를 보고 자동으로 결정한다는 뜻입니다. 신경망 학습에 대해서 설명하고 파이썬으로 MNIST 데이터셋의 손글씨 숫자를 학습하는 코드를 구현해보겠습니다.
1.1 데이터 주도 학습
기계학습이란 데이터에서 답을 찾고 데이터에서 패턴을 발견하고 데이터로 이야기를 만드는 것을 의미합니다.
주어진 문제를 해결하려 할 때 사람, 기계학습, 신경망(딥러닝) 세 종류의 접근법에 대해 알아보겠습니다.

사람 - 이것저것 생각하고 답을 찾습니다. 사람의 경험과 직관을 단서로 시행착오를 거듭하며 일을 진행합니다.
기계학습 - 모아진 데이터로부터 규칙을 찾아내는 역할을 '기계'가 담당합니다. 다만, 이미지를 벡터로 변환할 때 사용하는 특징은 여전히 '사람'이 설계해야 합니다.
신경망(딥러닝) - 이미지를 '있는 그대로' 학습합니다. 기계학습에서는 특징을 사람이 설계했지만, 신경망은 이미지에 포함된 중요한 특징까지도 '기계'가 스스로 학습합니다. 신경망은 모든 문제를 주어진 데이터 그대로 입력 데이터로 활용해 학습할 수 있습니다.

딥러닝을 종단간 기계학습(end to end machin learning)이라고도 합니다. 여기서 종단간은 '처음부터 끝까지'라는 의미로, 데이터(입력)에서 목표한 결과(출력)를 사람의 개입 없이 얻는다는 뜻을 담고 있습니다.
1.2 훈련 데이터와 시험 데이터
기계학습 문제는 데이터를 훈련 데이터(training data)와 시험 데이터(test data)로 나눠 학습과 실험을 수행합니다.
우선 훈련 데이터만 사용하여 학습하면서 최적의 매개변수를 찾습니다. 그런 다음 시험 데이터를 사용하여 앞서 훈련한 모델의 실력을 평가하는 것 입니다. 그 이유는 범용적으로 사용할 수 있는 모델을 구축해야 하기 때문입니다. 범용 능력을 제대로 평가하기 위해 훈련 데이터와 시험 데이터를 분리하는 것입니다.
범용 능력 : 아직 보지 못한 데이터(훈련 데이터에 포함되지 않는 데이터)로도 문제를 올바르게 풀어내는 능력입니다. 이 범용 능력을 획득하는 것이 기계학습의 최종 목표입니다. 예를 들어 손글씨 숫자 인식의 최종 모델은 엽서에서 우편 번호를 자동으로 판독하는 시스템에 쓰일 수 있습니다.
오버피팅 : 훈련 데이터셋에만 지나치게 최적화된 상태를 오버피팅이라고 합니다. 훈련 데이터셋은 제대로 맞히더라도 다른 데이터셋에는 엉망인 상태가 발생할 수 있습니다. 오버피팅 피하기는 기계학습의 중요한 과제입니다.
2. 손실함수
신경망은 '하나의 지표'를 기준으로 최적의 매개변수 값(가중치와 편향)을 탐색합니다. 이 지표를 손실 함수라고 합니다. 손실함수는 일반적으로는 평균 제곱 오차와 교차 엔트로피 오차를 사용합니다.
손실 함수는 신경망 성능의 '나쁨'을 나타내는 지표로, 현재 신경망이 훈련 데이터를 얼마나 잘 처리하지 '못'하느냐를 나타냅니다.
2.1 평균 제곱 오차
가장 많이 쓰이는 손실 함수는 평균 제곱 오차(MSE, mean squared error)입니다. 평균 제곱 오차는 수식으로 다음과 같습니다.

여기서 $y_{k}$는 신경망의 출력(신경망이 추정한 값), $t_{k}$는 정답 레이블, $k$는 데이터 차원 수를 나타냅니다. 예를 들어 '02-2 신경망(2)'에서 MNIST 구현의 $y_{k}$와 $t_{k}$는 다음과 같은 원소 10개짜리 데이터 입니다.
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0] # 소프트맥스 함수의 출력
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] # 정답을 가르키는 위치의 원소
평균 제곱 오차는 각 원소의 출력(추정 값)과 정답 레이블(참 값)의 차($y_{k}$ - $t_{k}$)를 제곱한 후, 그 총합을 구합니다. ($y_{k}$ - $t_{k}$)가 작으면 작을 수록 MSE는 낮아집니다.
평균 제곱 오차를 파이썬으로 구현해봅시다.
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t)**2) # 여기에서 인수 y와 t는 넘파이 배열입니다.
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] # 정답은 2
y1 = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0] # 2일 확률이 가장 높다고 추정함 (0.6)
print( mean_squared_error(np.array(y1), np.array(t)) )
>>> 0.0975000000031
y2 = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0] # 7일 확률이 가장 높다고 추정함 (0.6)
print( mean_squared_error(np.array(y2), np.array(t)) )
>>> 0.597500000003
평균 제곱 오차를 기준으로는 첫 번째 추정 결과가 (오차가 더 작으니) 정답에 더 가까울 것으로 판단할 수 있습니다.
2.2 교차 엔트로피 오차
또 다른 손실 함수로서 교차 엔트로피 오차(CEE, cross entropy error)도 자주 이용합니다.

$y_{k}$는 신경망의 출력, $t_{k}$는 정답 레이블입니다. 또, $t_{k}$는 정답에 해당하는 인덱소의 원소만 1이고 나머지는 0입니다.(원-핫 인코딩) 그래서 위 식은 실질적으로 정답일 때의 추정($t_{k}$가 1일 때의 $y_{k}$)의 자연로그를 계산하는 식이 됩니다 (정답이 아닌 나머지 모두 $t_{k}$가 0이므로 log$y_{k}$와 곱해도 0이 되어 결과에 영향을 주지 않습니다.)
예를 들어 정답 레이블은 '2'가 정답이라 하고 이떄의 신경망 출력이 0.6이라면 교차 엔트로피 오차는 -log0.6 = 0.51이 됩니다. 또한 같은 조건에서 신경망 출력이 0.1이라면 -log0.1 = 2.3이 됩니다.
즉, 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정하게 됩니다.

이 그림에서 보듯이 x가 1일 때는 y는 0이 되고, x가 0에 가까워질수록 y의 값은 점점 작아집니다. CEE식도 마찬가지로 정답에 해당하는 출력이 커질수록 0에 다가가다가, 그 출력이 1일 때 0이 됩니다. 반대로 정답일 때의 출력이 작아질수록 오차는 커집니다.
교차 엔트로피 오차 구현하기
def cross_entropy_error(y, t):
delta = 1e-7 # 아주 작은 값
return -np.sum(t * np.log(y + delta)) # np.log()에 0을 입력하면 마이너스 무한대를 의미하므로
# 계산이 되지 않는다. 따라서 아주 작은 값을 더해줬습니다.
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] # 정답은 2
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0] # 신경망이 2로 추정
print( cross_entropy_error(np.array(y), np.array(t) )
>>> 0.5108254709933802
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0] # 신경망이 7로 추정
print( cross_entropy_error(np.array(y), np.array(t) )
>>> 2.3025840929945458
오차가 더 작은 첫 번째 추정이 정답일 가능성이 높다고 판단한 것을 확인할 수 있습니다. 앞서 배운 평균 제곱 오차의 판단과 일치합니다.
2.3 미니배치 학습
미니배치: 훈련 데이터로부터 일부만 골라 학습을 수행합니다. 예를 들어 60,000장의 훈련 데이터 중에서 100장을 무작위로 뽑습니다.
미니배치 학습: 뽑아낸 100장만을 사용하여 학습하는 것을 의미합니다.
미니배치 이유: 모든 데이터를 대상으로 손실 함수의 합을 구하려면 시간이 걸립니다. 따라서 데이터 일부를 추려 전체의 '근사치'로 이용하여 시간을 단축시키려는 목적입니다.
지금까지 데이터 하나에 대한 손실 함수만 생각해왔으니, 이제 훈련 데이터 모두에 대한 손실 함수의 합을 구하는 방법을 생각해보겠습니다.

이때, 데이터가 N개라면 $t_{nk}$는 n번째 데이터의 $k$번째 값을 의미합니다. ($y_{nk}$는 신경망의 출력, $t_{nk}$는 정답 레이블입니다.) 이 식은 데이터 하나에 대한 손실 함수의 식을 단순히 N개의 데이터로 확장했을 뿐입니다.
다만, 마지막에 N으로 나누어 정규화하고 있습니다. N으로 나눔으로써 '평균 손실 함수'를 구하는 것입니다.
이렇게 평균을 구해 사용하면 훈련 데이터 개수와 관계없이 언제든 통일된 지표를 얻을 수 있습니다.
미니배치를 구현해보겠습니다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize = True, one_hot_label = True)
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000, 10)
데이터를 불러왔습니다. 자세한 내용은 여기에서 확인하실 수 있습니다.
train_size = x_train.shape[0] # 60000 의미
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size) # 60000개 중 10개 뽑기
# np.random.choice를 이용해 무작위로 원하는 개수만 꺼낼 수 있습니다.
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
2.4 (배치용) 교차 엔트로피 오차 구현하기
t가 원-핫 인코딩 일때
def cross_entropy_error(y, t):
if y.ndim == 1: # 배치사이즈가 1일때
t = t.reshape(1, t.size) # 1-D 로 변환, t.size는 t의 요소 갯수를 의미
y = y.reshape(1, y.size) # 1-D 로 변환
batch_size = y.shape[0] # y의 배치 사이즈
return -np.sum(t * np.log(y)) / batch_size # 원핫인코딩일 경우
# t가 0일때는 교차 엔트로피 오차도 0이므로
# 무시해도 좋다는 것이 핵심t * np.log(y) 이므로 t가 0일 때 교차 엔트로피 오차도 0이 되므로 무시해도 좋다는 것이 핵심입니다.
t가 원-핫 인코딩 아닐 때 (레이블 표현)
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0] # 배치 사이즈를 의미
return -np.sum( np.log( y[np.arange(batch_size), t] )) / batch_size # 원핫인코딩이 아닐경우
원-핫 인코딩 시 t * np.log(y)
원-핫 인코딩이 아닐 경우 np.log( y[ np.arange(batch_size), t] )로 구현합니다.
np.log( y[ np.arrange(batch_size), t] ) 설명
np.arrange(batch_size)는 0부터 batch_size -1 까지 배열을 생성합니다.
batch_size가 5이면 [0, 1, 2, 3, 4] 넘파이 배열을 생성합니다.
t에는 레이블이 [2, 7, 0, 9, 4]와 같이 저장되어 있으므로
y[np,arange(batch_size), t]는 각 데이터의 정답 레이블에 해당하는 신경망의 출력을 추출합니다.
따라서, [ y[0,2], y[1,7], y[2,0], y[3,9], y[4,4] ] 인 넘파이 배열을 생성합니다.
y = [ [ 0.1, 0.3, 0.05, 0.1, ~ ]
[ 0.6, 0.1, 0.2, 0.05 ~ ] 일때 y[0,2] 는 0.3을 의미합니다.
2.5 왜 손실 함수를 설정하는가?
궁극적인 목적은 높은 '정확도'를 끌어내는 매개변수 값을 찾는 것 입니다. 그렇다면 '정확도'라는 지표를 놔두고 '손실 함수의 값'이라는 우회적인 방법을 택하는 이유를 알아보겠습니다.
신경망 학습에서의 '미분'의 역할에 주목하면 해결 됩니다.
신경망 학습에서는 손실함수의 미분(기울기)를 계산하고, 미분 값이 0이 되는 쪽으로 매개변수를 갱신해줍니다.
정확도를 지표로 삼아서는 안 되는 이유는 미분 값이 대부분의 장소에서 0이 되어 매개변수를 갱신할 수 없기 때문입니다. 정확도는 매개변수의 미소한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화합니다.
이는 '계단 함수'를 활성화 함수로 사용하지 않는 이유와 같습니다.
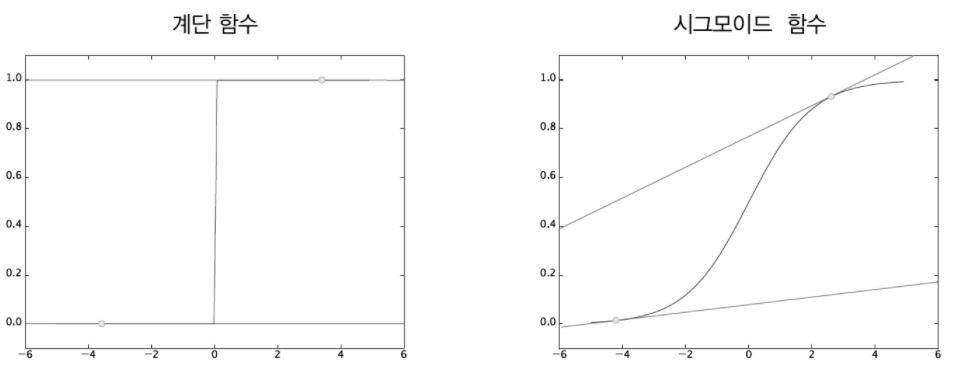
계단 함수의 미분은 대부분의 장소에서 기울기가 0이지만, 시그모이드 함수의 미분은 출력이 연속적으로 변하고 곡선의 기울기도 연속적으로 변합니다. 즉, 시그모이드 함수의 미분은 어느 장소라도 0이 되지는 않습니다.
이는 신경망 학습에서 중요한 성질로, 기울기가 0이 되지 않는 덕분에 신경망이 올바르게 학습할 수 있는 것입니다.
3. 수치 미분 (Numerical differentiation)
경사법에서는 기울기(경사) 값을 기준으로 나아갈 방향을 정합니다. 기울기와 경사법을 공부하기 전에 '미분'부터 공부해보겠습니다.
수치미분이란?
'해석적 미분'은 우리가 수학 시간에 배운 오차를 포함하지 않는 '진정한 미분' 값을 구해줍니다. '수치 미분'은 이를 '근사치'로 계산하는 방법입니다. 따라서 오차가 포함됩니다. 이와 관련하여 수치해석학은 '해석학 문제에서 수치적인 근삿값을 구하는 알고리즘을 연구하는 학문'입니다.
3.1 미분
미분은 한순간의 변화량을 표시한 것입니다.

$x$의 '작은 변화'가 함수 $f(x)$를 얼마나 변화시키느냐를 의미합니다. 이때 시간의 작은 변화, 시간을 뜻하는 $h$를 한없이 0에 가깝게 한다는 의미를 $\lim_{h \rightarrow 0}$로 나타냅니다.
이제 미분을 구현해봅시다.
# 나쁜 구현 예
def numerical_diff(f, x):
h = 10e - 50
return (f(x + h) - f(x)) / h
개선해야 할 점이 2개 있습니다.
1. 반올림 오차 문제
반올림 오차는 작은 값(소수점 8자리 이하)이 생략되어 최종 계산 결과에 오차가 생기게 합니다. h를 0으로 무한히 가깝게 하기 위해 10e - 50 이라는 작은 값을 이용했습니다. 이 방식은 반올림 오차 문제를 일으킵니다. 너무 작은 값을 이용하면 컴퓨터로 계산하는 데 문제가 생깁니다.
>>> $10^{-4}$ 정도의 값을 사용하면 좋은 결과를 얻는다고 알려져 있습니다.
2. 함수 f의 차분 문제 ( 차분은 임의의 두 점에서의 함수 값들의 차이를 말합니다.)
앞의 구현에서 $x$ + $h$와 $x$ 사이의 함수 $f$의 차분을 계산하고 있지만, 이 계산에는 오차가 있습니다. 진정한 미분은 $x$ 위치의 함수의 기울기(접선)에 해당하지만, 이 구현에서의 미분은 ($x$ + $h$)와 $x$ 사이의 기울기에 해당합니다. 이 차이는 $h$를 무한이 0으로 좁히는 것이 불가능해 생기는 한계입니다.
>>> 오차를 줄이기 위해 중심 차분 혹은 중앙 차분을 이용합니다.
중심 차분, 중앙 차분이란?
($x$ + $h$)와 ($x$ - $h$)일 때의 함수 $f$의 차분을 계산하는 방법을 의미합니다. 이 차분은 $x$를 중심으로 그 전후의 차분을 계산한다는 의미에서 중심 차분 혹은 중앙 차분이라 합니다. (한편, ($x$ + $h$)와 x의 차분은 전방 차분이라 합니다.)

두 개선점을 적용해 수치 미분을 구현해봅시다.
def numerical_diff(f, x):
h = 1e - 4 #0.0001
return (f(x+h) - f(x-h)) / (2 * h) # 중앙 차분 이용
3.2 수치 미분의 예
앞 절의 수치 미분을 사용하여 간단한 함수를 미분해봅시다. 우선 다음과 같은 2차 함수입니다.
$y$ = 0.01$x^2$ + 0.1$x$
파이썬으로 구현
def function_1(x):
return 0.01 * x ** 2 + 0.1 * x
이어서 함수를 그려봅시다.
import numpy as np
import matplotlib.pylab as plt
x = np.arange(0.0, 20.0, 0.1) # 0에서 20까지 0.1 간격의 배열 x를 만듭니다.
y = function_1(x)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.plot(x, y)
plt.show()
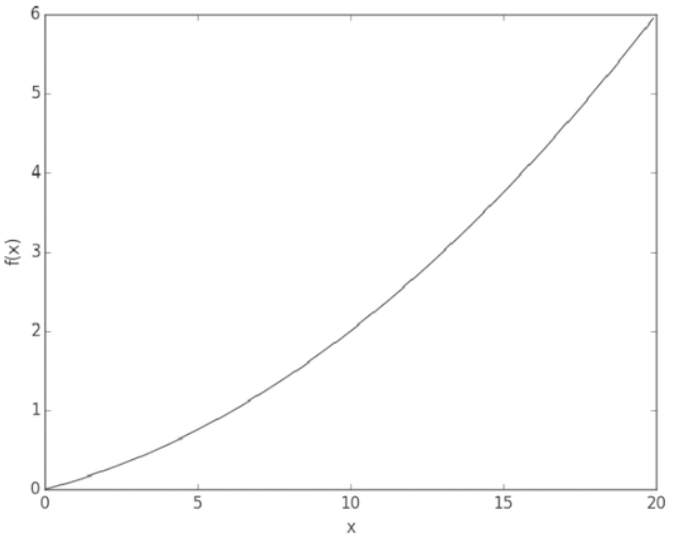
그럼 $x$ = 5 일 떄와 10일 때 이 함수의 미분을 계산해봅시다.
numerical_diff(function_1, 5)
>>> 0.19999999
numerical_diff(function_1 ,10)
>>> 0.29999999
이렇게 계산한 미분 값이 $x$에 대한 $f$($x$)의 변화량입니다. 즉 함수의 기울기에 해당합니다.
해석적 미분 결과는 (0.2, 0.3) 입니다. 이와 비교하면 오차가 매우 적음을 알 수 있습니다.
다음은 수치 미분 값을 기울기로 하는 직선을 그려보겠습니다.
import numpy as np
import matplotlib.pylab as plt
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)
def function_1(x):
return 0.01*x**2 + 0.1*x
def tangent_line(f, x): # 접선의 함수를 반환하는 함수
d = numerical_diff(f, x) # 수치미분값 ( 접선의 기울기 의미)
print(d)
y = f(x) - d*x # 접선의 절편
return lambda t: d*t + y # 접선의 함수 t 반환
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
tf = tangent_line(function_1, 5) # x = 5 일 때 접선의 함수 생성
y2 = tf(x) # x범위 만큼의 접선의 함수 결과값
plt.plot(x, y) # 함수 f(x)
plt.plot(x, y2) # 접선
plt.show()

3.3 편미분
편미분은 변수가 여럿인 함수에 대한 미분을 의미합니다.
$f$($x_0$, $x_1$) = $x_{0}^{2}$ + $x_{1}^{2}$
이 식은 변수가 2개입니다.
파이썬으로 구현
def function_2(x):
return x[0] ** 2 + x[1] ** 2
# 또는 return np.sum(x ** 2)
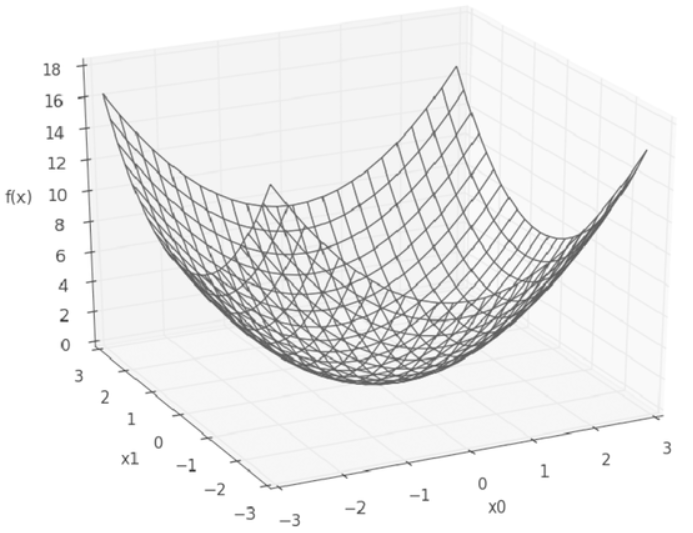
이제 미분을 해봅시다. 변수가 2개 이므로 $x_0$와 $x_1$ 중 어느 변수에 대한 미분이냐를 구별해야 합니다.
이 편미분을 수식으로 $\frac{\partial f}{\partial x_0}$ 나 $\frac{\partial f}{\partial x_1}$ 처럼 씁니다.
이제 편미분을 구현해보겠습니다.
x0 = 3
x1 = 4
def function_tmp1(x0): # x0에 대한 편미분
return x0 * x0 + 4.0 ** 2.0
numerical_diff(function_tmp1, 3.0)
>>> 6.000000378
def function_tmp2(x1): # x1에 대한 편미분
return 3.0 ** 2.0 + x1 ** x1
numerical_diff(function_tmp2, 4.0)
>>> 7.99999999119
다른 변수는 값을 고정하고 목표 변수 하나에 초점을 맞추었습니다. 목표 변수를 제외한 나머지를 특정 값에 고정하기 위해서 새로운 함수를 정의했습니다. 그리고 새로 정의한 함수에 그동안 사용한 수치 미분 함수를 적용하여 편미분을 구한 것 입니다.
다음 포스팅에서는 손실 함수의 기울기를 구하고 경사법으로 손실 함수 결과값을 최소화 시키는 방법을 알아보겠습니다. 감사합니다.
'수학 > 딥러닝 이론' 카테고리의 다른 글
| 03-3. 신경망 학습 (3) - 학습 알고리즘 구현 (1) | 2020.09.11 |
|---|---|
| 03-2. 신경망 학습 (2) - 기울기와 경사하강법 (0) | 2020.09.11 |
| 02-2. 신경망 (2) - 출력층 설계와 MNIST 구현 (6) | 2020.09.09 |
| 02-1. 신경망 (1) - 3층 신경망 순전파 구현 (0) | 2020.09.09 |
| 01. 퍼셉트론 - Perceptron (3) | 2020.09.06 |