서포트 벡터 분류기(Support Vector Classifiers)

위 그림 같은 경우에 training observation은 분리 초평면(separating hyperplane)에 의해 분류되지 않습니다. 이처럼 두 class에 속하는 관측치(observation)들이 항상 초평면에 의해 분류되는 것은 아닙니다.

또한 관측치가 하나 추가되면 위 그림처럼 초평면이 급격하게 변화될 수 있습니다. 마진이 급격하게 감소했는데 마진은 observation에 할당된 class의 확신을 의미하므로 문제가 발생할 수 있습니다. 이처럼 분리 초평면에 기반한 분류기는 하나의 개별 관측치에 민감하게 반응할 수 있습니다. 또한 과적합을 유발할 수 있습니다.
이 경우에 관측값들을 완벽하게 두 클래스로 분리하지 않는 초평면에 기반하는 분류기를 고려할 수 있습니다. (1) 개별 관측치에 robustness하며 (2) 대부분의 training observation을 더 잘 분류하는 목적으로 분류기를 구성해야 합니다.
즉, 전체적인 관측치들을 잘 분류하기 위하여 소수의 관측치들을 오분류 할만한 가치가 있습니다.
이러한 목적으로 설계된 분류기가 서포트 벡터 분류기(support vector classifier) 혹은 소프트 마진 분류기(soft margin classifier) 입니다. 모든 관측치에 대해 가장 큰 마진을 찾기보다 margin의 잘못된 면에 몇몇의 관측치들이 위치하는 것을 허용합니다. 아래 그림은 예시입니다.
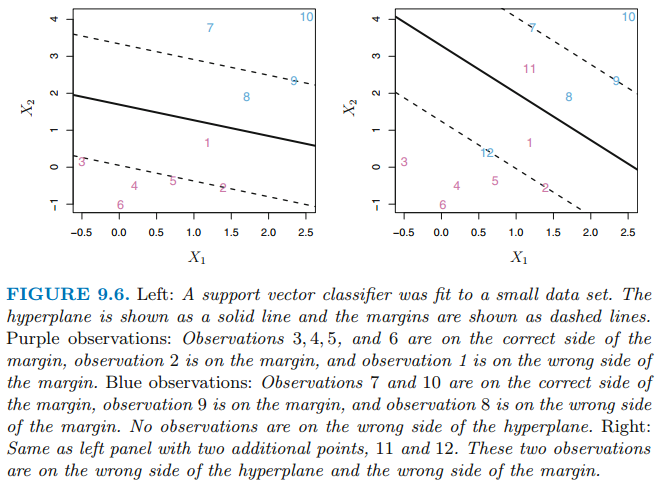
이처럼 대부분의 관측치들은 마진의 올바른 면에 놓여있고 관측치들의 작은 부분 집합은 마진의 잘못된 면에 놓여져 있습니다. 실제로 분리 초평면이 없을 때 이런 상황은 피할 수 없습니다. 초평면의 잘못된 면에 놓여져 있는 관측치는 분류기가 오분류 한것을 의미합니다.
서포트 벡터 분류기의 세부 사항(Details of the Support Vector Classifier)
서포트 벡터 분류기는 초평면의 어느 면에 test observation이 놓이느냐에 따라 분류합니다. 초평면은 training observation을 두 개의 classes로 분류하고 몇 개의 observation은 오분류 하도록 선택합니다. 이는 아래의 최적화 문제를 푸는 것과 동일합니다.

C는 non-negative 조율 파라미터(tuning parameter) 입니다. M은 margin의 넓이를 의미하여 이 M을 최대화하는 방향으로 $\beta$를 선택해야 합니다. $\epsilon$은 매 i 번째 observation마다 C보다 작은 값으로 선택되어 margin의 양을 조절합니다. 그리고 슬랙 변수(slace variable)이라고 부릅니다. 이 슬랙 변수가 개별 관측치 들이 잘못된 마진에 속하게 하도록 합니다.
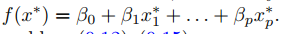
test observation $x^*$는 f($x^*$)의 부호에 따라 class를 할당합니다.
슬랙 변수 $\epsilon$은 i번째 관측치가 margin에 상대적으로 어디에 놓여야하는지를 결정합니다. 만약에 슬랙 변수가 0이면 i번째 관측치는 마진의 옭은 면에 놓이고 슬랙 변수가 0보다 크면 i번째 관측치는 margin의 잘못된 면에 놓입니다. 이를 i번째 관측치가 마진을 위반한다고 표현합니다. 만약에 슬랙 변수가 1보다 크면 관측치는 초평면의 잘못된 부분에 놓입니다.
조율 파라미터 C는 $\epsilon$의 합의 경계를 결정합니다. 이는 margin을 위반하는 수와 정도를 결정합니다. C를 n개의 관측치들에 의해 위반되는 margin의 양에 대한 예산이라고 생각할 수 있습니다. C=0이면 margin을 위반하는 관측치는 존재하지 않고 이는 단순히 최대 마진 초평면 분류기의 최적화 문제가 됩니다. C > 0 인 경우 C 이하의 관측치들이 초평면의 잘못된 면에 놓여질 수 있습니다.
C가 증가함에 따라 마진 위반에 대한 허용 정도가 점점 더 처져 마진의 폭이 넓어질 것입니다. C가 작아질수록 마진 위반에 대한 허용 정도가 작아져 margin은 점점 좁아집니다.

C는 cross-validation을 통해 선택합니다. 조율 파라미터는 bias-variance의 trade-off를 조율하듯이 C도 마찬가지 입니다. C가 작으면 드물게 위반하는 좁은 margin이 선택되고 이는 low bias와 high variance인 과적합을 발생할 수 있습니다. 반면에 C가 크면 마진 위반을 허용하는 넓은 margin이 선택되고 high bias와 low variance를 갖습니다.
서포트 벡터 분류기는 margin 상에 놓여있거마 margin을 위반하는 관측치들만이 초평면에 영향을 줍니다. 따라서 분류기는 이들에 의해 얻어집니다. 다른 말로하면 margin의 옳은 면에 놓여있는 관측치들은 서포트 벡터 분류기에 영향을 미치지 않습니다.
마진상에 놓여 있거나 클래스에 대한 마진의 옳지 않은 쪽에 놓여 있는 관측치들은 서포트 벡터라고 부르며 이 서포트 벡터만이 서포트 벡터 분류기에 영향을 미칩니다.
서포트 벡터 머신의 겨정 규칙이 training observation의 작은 부분 집합에 기반한다는 사실은 초평면으로부터 멀리 떨어져 있는 관측값의 행동에 robust 하다는 것을 의ㅣ합니다. 이 성질은 다른 분류 방법들과 다릅니다. LDA 분류기는 각 class내에 존재하는 모든 관측치들의 평균과 모든 관측치를 사용해 계산한 클래스 내 공분산 행렬(within-class covariance matrix)에 의존했습니다. LDA와 달리 logistic regression은 결정 경계와 멀리 떨어진 관측치들에 대하여 매우 낮은 민감도를 갖습니다. 이 서포트 벡터 분류기와 로지스틱 회귀는 밀접하게 관련되어 있는데, 이에 대해 추후에 살펴보겠습니다.
참고자료 및 그림 출처
Gareth James의 An Introduction to Statistical Learning
'수학 > Statistical Learning' 카테고리의 다른 글
| [ISLR] 서포트 벡터 머신(SVM, Support Vector Machine) (0) | 2021.08.03 |
|---|---|
| [ISLR] 비선형 결정 경계(Non-linear Decision Boundaries) (0) | 2021.08.03 |
| [ISLR] 최대 마진 분류기(The Maximal Margin Classifier) (0) | 2021.08.02 |
| [ISLR] 부스팅(Boosting) (0) | 2021.07.31 |
| [ISLR] 랜덤 포레스트(Random Forests) (0) | 2021.07.31 |