랜덤 포레스트(Random Forests)
랜덤 포레스트는 트리들의 상관성을 제거하는 방법(decorrelate)으로 bagged tree에 대해 성능 향상을 제공합니다. bagging을 수행하기 위하여 decision tree를 구축해야 합니다. decision tree를 구축할 때, 전체 p개의 변수들 중에서 무작위 m개의 변수들로 분할을 수행할 것인지 고려해야 합니다. 분할은 이 m개의 변수중 하나만을 사용하여 진행하고, 각 분할에서 새로운 m개의 변수를 추출합니다. 일반적으로 m = $\sqrt{q}$로 선정합니다. 예를 들어 p=13이면 m=4를 선택합니다.
다른 말로하면, random forest를 만드는 도중에 트리의 각 분할에서 알고리즘은 사용가능한 다수의 변수들을 고려하는 것이 허용되지 않습니다. 만약 데이터셋에 하나의 강력한 변수가 존재한다고 가정하겠습니다. 그리고나서 bagged trees에서 대부분의 트리가 top split에 이 강력한 변수를 사용할 것입니다. 그 결과 모든 bagged trees는 서로 비슷해 보일 것입니다. 따라서 bagged trres로부터의 예측값은 매우 correlated 될 것입니다. 매우 높은 상관성을 갖는 값들으 평균하는 것은 분산을 크게 줄이지 않습니다. 이러한 예시에서 bagging은 단일 트리에 대한 분산을 크게 감소시키지 않습니다.
랜덤 포레스트는 각 분할이 변수의 부분집합만을 고려하게하여 이 문제를 해결합니다. 그러므로 평균적으로 (p - m) / p 번의 분할은 강한 변수를 고려하지 않을 것이고 다른 변수들은 더 많은 기회를 얻습니다. 이 과정을 트리들의 상관성을 제거하는 것으로 생각할 수 있습니다. 그러므로 결과 트리의 평균은 variable이 낮아져 더 신뢰성 있는 모델이 됩니다.
배깅과 랜덤 포레스트의 차이는 변수의 부분 집합 크기 m의 선택입니다. 예를 들어, 랜덤 포레스트에서 m=p를 선택하면 이는 배깅이 됩니다.
또한 상관성을 가진 변수들이 많은 경우에 적은 수의 m을 선택하는 것이 유용합니다.
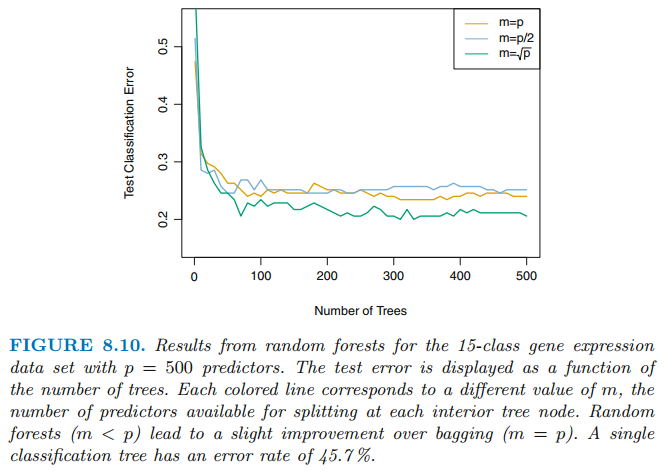
배깅과 같이 랜덤 포레스트는 B가 증가한다고 과적합이 되지 않습니다. 실제로는 상당히 큰 B값을 사용하면 error rate는 안정됩니다.
참고자료 및 그림 출처
Gareth James의 An Introduction to Statistical Learning
'수학 > Statistical Learning' 카테고리의 다른 글
| [ISLR] 최대 마진 분류기(The Maximal Margin Classifier) (0) | 2021.08.02 |
|---|---|
| [ISLR] 부스팅(Boosting) (0) | 2021.07.31 |
| [ISLR] 배깅(Bagging) (0) | 2021.07.31 |
| [ISLR] 트리와 선형 모델, 트리의 장단점 (0) | 2021.07.30 |
| [ISLR] 분류 트리(Classification Tree) (0) | 2021.07.30 |