분류 트리(Classification Tree)
분류 트리는 이전에 공부했었던 회귀 트리와 매우 유사하며 차이점은 양적 반응 변수가 아니라 질적 반응 변수를 예측한다는 것입니다. 회귀 트리는 관측값이 속한 terminal node의 평균값을 사용하여 예측했습니다. 이와 반대로 분류 트리는 관측치가 속하는 구역에서 훈련 관측치의 가방 빈번하게 발생하는 클래스에 관측치가 해당하는지를 예측합니다. 따라서 터미널 노드에 해당하는 클래스 예측값(class prediction) 뿐만 아니라 그 구역에 해당하는 훈련 관측치들의 클래스 비율(class proportion)에도 관심이 있습니다.
분류 트리를 구축하기 위해 회귀 트리와 마찬가지로 재귀 이진 분할을 사용합니다. 이진 분할을 위한 기준으로 RSS는 사용할 수 없으므로 대신에 분류 오류율(classification error rate)을 사용합니다. 주어진 영역 내의 관측치를 그 영역 내의 훈련 관측치들의 가장 빈번하게 발생하는 클래스에 할당하기 때문에, 분류 오류율은 해당 구역내 훈련 관측치들이 가장 빈번한 클래스에 속하지 않는 부분입니다.

$\hat{p}_{mk}$는 m구역 내의 k class에 속하는 훈련 관측치들의 비율입니다. 하지만 이 방법은 트리를 구축하는데에 충분하지 않아 다른 두 가지 척도를 사용합니다.
첫 번째는 지니 지수(Gini index) 입니다.
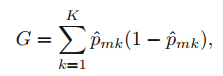
지니 지수는 K개 클래스에 걸친 총 분산의 측도입니다. $\hat{p}_{mk}$가 0또는 1에 가까우면 지니 지수는 작은 값을 갖습니다. 이러한 이유로 지니 지수는 노드 순도(purity)라고 불르며 작은 값은 노드가 단일 클래스를 지닌 관측치에 의해 지배된다는 것을 나타냅니다. 즉, 구역 내의 훈련 관측값들이 단일 클래스만을 지닌다는 것을 의미합니다.
다른 criterion은 크로스 엔트로피 입니다.

만약 $\hat{p}_{mk}$가 0또는 1에 가까운 값을 갖는다면 cross-entropy는 0에 가까운 값을 갖습니다. 그러므로 m번째 노드가 순수하다면 지니 계수와 크로스 엔트로피는 작은 값을 갖습니다.
지니 계수와 크로스 엔트로피는 노드의 순수성을 측정하므로 특정 분할의 수준을 평가하기위해 사용합니다. 위에서 살펴본 3가지 방법은 트리를 pruning하기 위해 사용될 수 있으며 최종적으로 pruning된 트리의 정확도가 목적이라면 분류 오류율이 선호됩니다.

참고자료 및 그림 출처
Gareth James의 An Introduction to Statistical Learning
'수학 > Statistical Learning' 카테고리의 다른 글
| [ISLR] 배깅(Bagging) (0) | 2021.07.31 |
|---|---|
| [ISLR] 트리와 선형 모델, 트리의 장단점 (0) | 2021.07.30 |
| [ISLR] Tree Pruning (0) | 2021.07.28 |
| [ISLR] 회귀 트리(Regression Trees) (0) | 2021.07.28 |
| [ISLR] 계단 함수(Step Functions) (0) | 2021.07.25 |