배깅은 강력한 예측 모델을 구축하기위해 트리를 buidling block으로 사용합니다.
배깅(Bagging)
이전에 공부했었던 부트스트랩(bootstrap)은 관심있는 양의 표준 편차를 계산하기 어려운 상황에서 사용하는 강력한 아이디어 입니다. 이 부트스트랩을 결정트리와 같은 통계 방법 성능을 향상시키기 위해 완전히 다른 맥락으로 사용할 수 있습니다.
결정트리(decision tree)는 high variance가 문제 됩니다. 이는 학습 데이터를 무작위로 두 부분으로 분할하고 의사 결정 트리를 두 부분에 적합하면 두 결과가 상당히 다를 수 있다는 것을 의미합니다. 반면에 low variance는 서로 다른 데이터셋에 반복적으로 적합을 진행해도 동일한 결과를 생성하는 것을 의미합니다.
부트스트랩 통합(bootstrap aggregation) 또는 배깅(bagging)은 통계 학습 모델의 variance를 감소시키기 위한 범용 절차(general-purpose procedure) 입니다. 왜 분산을 감소시킬까요?
n개의 독립적인 관측치 $Z_1, ... ,Z_n$가 주어진 경우에 분산은 $\sigma ^2$로 주어지고 관측치의 평균의 분산은 $\sigma ^2/n$ 입니다. 즉 관측치 집합의 평균은 분산을 감소시킵니다. 분산을 감소시키고 정확도를 향상시키는 방법은 많은 데이터를 취하여 개별 모델 예측값을 계산한 후 최종 예측값에 평균을 취하는 것입니다.
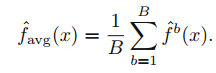
B개의 개별 training set에 대하여 B번 예측값을 계산하여 평균을 취하면 단일 low-variance 통계 모델을 얻을 수 있습니다.
일반적으로 다수의 training set을 얻는 것은 현실적이지 않습니다. 대신에 단일 training set으로부터 sampling을 반복하는 bootstrap을 사용할 수 있습니다. B개의 서로다른 bootstrap된 training dataset을 생성한 뒤 B개의 model prediction을 계산하고 평균을 합니다. 이것이 배깅입니다.

배깅은 특히 결정 트리에 유용합니다. 배깅을 회귀 트리에 적용하면 B개의 부트스트랩 학습셋을 생성한 후 B개의 회귀 트리를 구축하여 예측을 수행하고 모든 결과값에 대하여 평균을 계산합니다. 각 tree는 prunning 하지 않아 높은 variance를 갖고 있지만 bagging을 해주어 variance를 감소합니다. 심지어 수백개 혹은 수천개의 트리를 함께 결합하여 성능을 향상시킬 수 있습니다.
분류 트리의 경우에 각 B개의 트리에 대하여 class 예측값을 기록하고 가장 자주 발생하는 class를 취합니다.
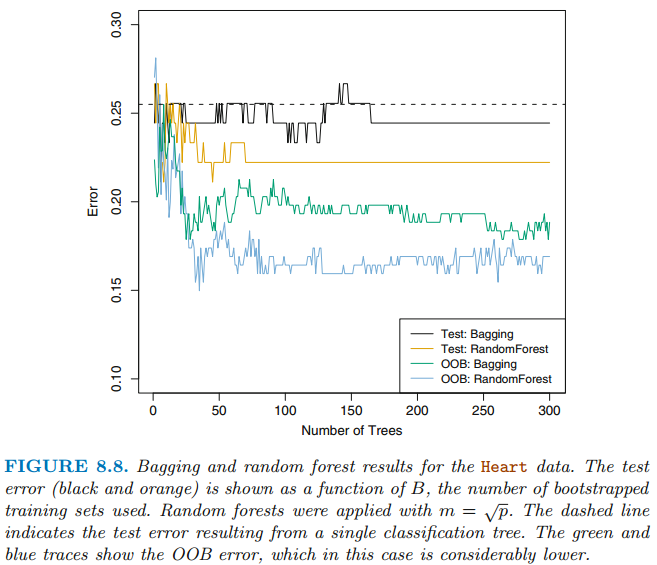
단일 트리로부터 얻은 test error보다 bagging을 수행하여 얻은 test error가 약간 더 낮습니다. 트리의 수 B는 배깅에서 중요한 파라미터가 아닙니다. 높은 수의 B를 사용하는 것은 과적합을 초래하지 않으므로 test error가 안정될때까지 충분히 큰 B를 사용합니다.
Out-of-Bag 오차 추정(Error Estimation)
cross-validation 또는 validation set 방법 없이 배깅 모델의 test error를 추정하는 직관적인 방법이 있습니다. 배깅은 bootstraped된 학습 부분 집합에 반복적으로 tree를 적합합니다. 평균적으로 각 배깅된 트리는 대략적으로 관측값들의 2/3 만을 사용하는데, 적합에 사용되지 않는 남은 1/3을 out-of-bag(OOB) 관측값이라고 합니다.
관측치가 OOB 이었던 트리를 사용하여 i 번째 관측치에 대한 반응 변수를 예측할 수 있습니다. 이는 i번째 관측치에 대해 B/3 개의 예측값을 생성합니다. i번째 관측치에대한 단일 예측값을 얻기 위해 이 예측된 반응변수들을 평균(회귀인 경우) 혹은 다수결(분류인 경우)할 수 있습니다. 이는 i번째 관측치에 대한 단일 OOB 예측값을 제공합니다. 이러한 방법으로 OOB MSE 혹은 분류 오류율을 계산하여 각 n개의 관측치에 대해 OOB 예측값을 얻을 수 있습니다.
결과 OOB error는 bagged model에 대한 test error의 유효한 추정치 입니다. 각 관측치에 대한 반응변수는 이 관측치를 사용하지 않은 트리로만을 사용하여 예측하기 때문입니다.
위 그림을 보면 OOB error가 충분히 낮다는 것을 알 수 있습니다. 또한 cross-validation을 수행하기 어려운 큰 데이터셋에 bagging을 수행할 때 OOB 방법은 유용합니다.
변수의 중요도 측정
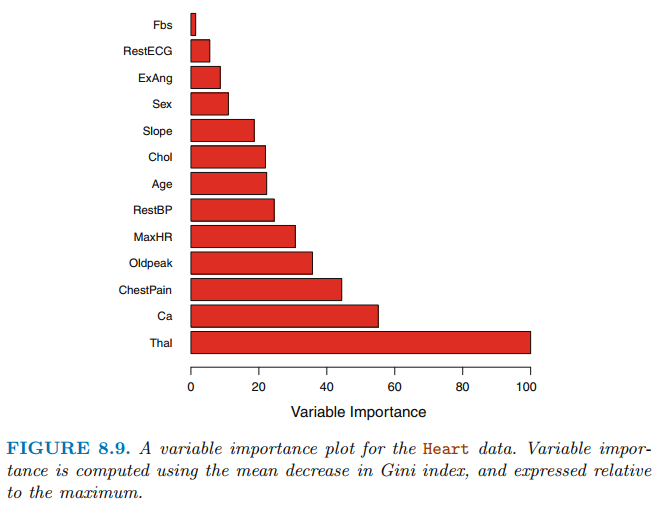
배깅은 성능을 향상시켜주지만 결과 모델을 해석하기가 어렵습니다. bag는 많은 수의 트리를 사용하기 때문에 어떤 변수가 중요한지 식별하는 것은 어렵습니다. 따라서, 배깅은 예측 정확도는 향상시키지만 해석은 오히려 더 어렵게 만듭니다.
RSS(회귀 트리의 경우) 혹은 Gini 계수(분류 트리인 경우)를 사용하여 각 변수의 중요도를 얻을 수 있습니다. 회귀 트리에 배깅을 수행하는 경우에 주어진 변수에 대한 분할에 의해 감소되는 RSS 저도를 기록하고 모든 B tree에 대하여 평균을 계산합니다. 가장 큰 값이 중요한 변수임을 나타냅니다. 이와 비슷한 맥락으로 분류 회귀에서 배깅을 수행하는 경우에 주어진 변수로 분할하여 감소되는 Gini 계수의 총양을 기록하고 모든 B개의 트리에대하여 평균을 취할 수 있습니다.
참고자료 및 그림 출처
Gareth James의 An Introduction to Statistical Learning
'수학 > Statistical Learning' 카테고리의 다른 글
| [ISLR] 부스팅(Boosting) (0) | 2021.07.31 |
|---|---|
| [ISLR] 랜덤 포레스트(Random Forests) (0) | 2021.07.31 |
| [ISLR] 트리와 선형 모델, 트리의 장단점 (0) | 2021.07.30 |
| [ISLR] 분류 트리(Classification Tree) (0) | 2021.07.30 |
| [ISLR] Tree Pruning (0) | 2021.07.28 |