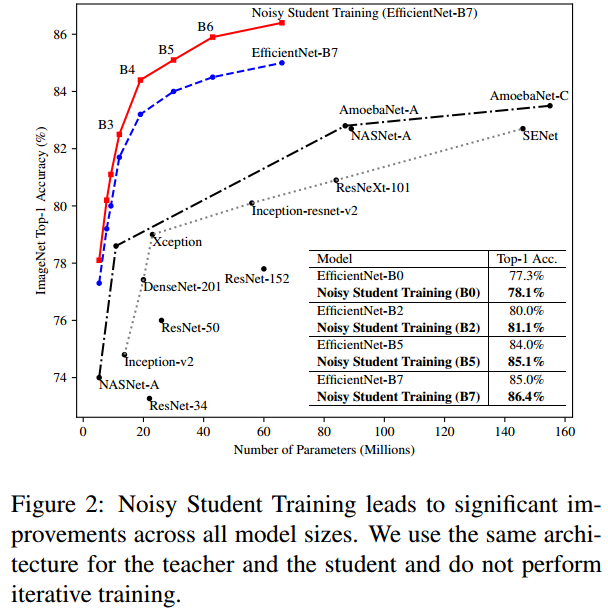
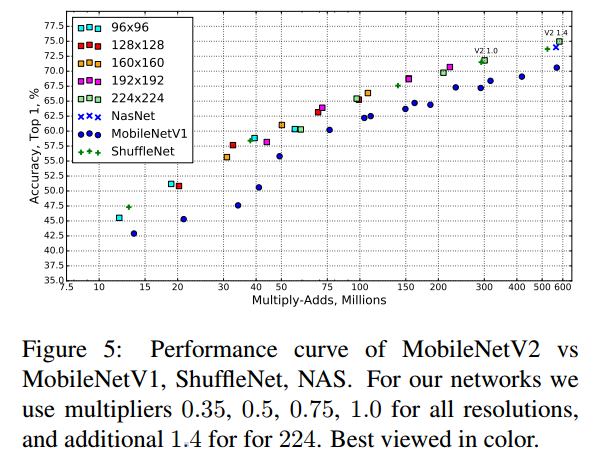
안녕하세요! 이번에 읽어볼 논문은 2020년에 Noisy Student의 성능을 뛰어넘고 SOTA를 달성한 FixEfficientNet, Fixing the train-test resolution 입니다. train data 수를 늘리기 위해서 random crop augmentation을 적용합니다. crop을 한 뒤에 resize로 크기를 조정하여 CNN 입력으로 넣어주는 것이 random crop 입니다. 하지만 test dataset에는 random crop을 적용하지 않고, 그냥 center crop만 적용하여 입력으로 넣어줍니다. 이때문에 train dataset의 분포와 test dataset의 분포에 차이가 생깁니다. 그리고 이 차이는 모델의 성능 하락으로 이어집니다. 이 문제를 해결하기 ..