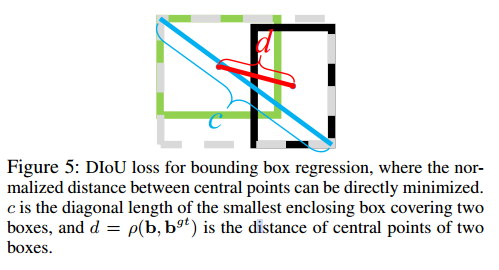
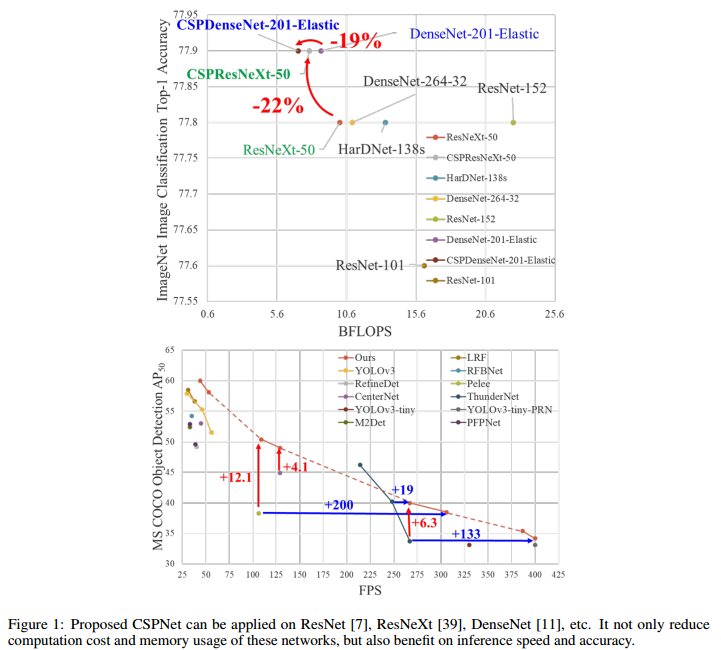
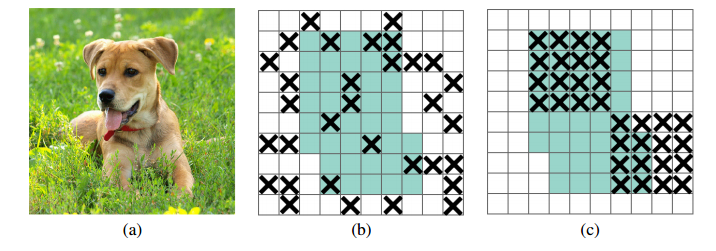
안녕하세요, 오늘 읽은 논문은 PANet, Path Aggregation Network for Instance Segmentation 입니다. PANet은 Mask R-CNN을 기반으로 Instance Segmentation을 위한 모델입니다. 이 논문에서 제안하는 Bottom-up path augmentation과 Adaptive feature pooling 방법은 YOLOv4에서 사용할 만큼 효과적인 성능을 나타내고 있습니다. PANet PANet은 (1) Bottom-up Path Augmentation, (2) Adaptive Feature Pooling, (3) Fully-connected Fusion 세 가지 방법을 제안합니다. 1. Bottom-up Path Augmentation Botto..