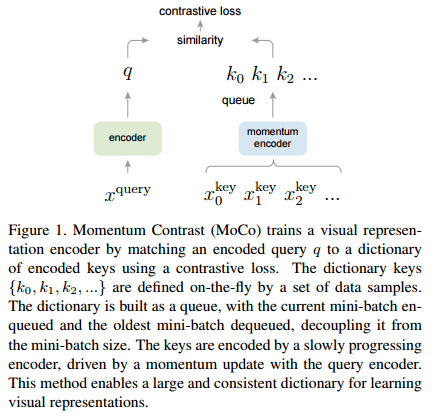
안녕하세요, 오늘 읽은 논문은 A Simple Framework for Contrastive Learning of Visual Representations 입니다. 해당 논문은 self supervised learning에서 major component를 연구합니다. 그리고 이 component를 결합하여 sota 성능을 달성합니다. 논문에서 설명하는 major component는 다음과 같습니다. (1) data augmentation contrastive learning은 batch내에 이미지를 추출하여 2개의 transformation을 적용해 각각 query와 key를 생성합니다. 동일한 image에 적용된 transformation은 similar이고, 나머지 batch에 존재하는 다르 이미지에..