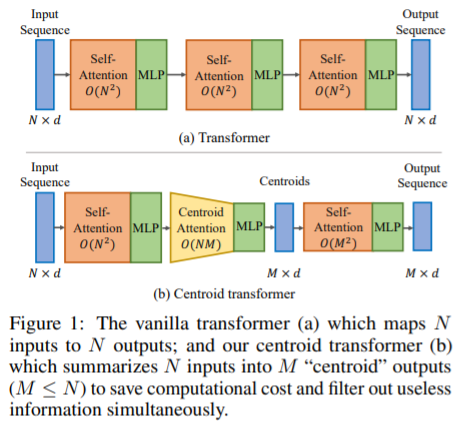
Centroid Transformers: Learning to Abstract with Attention Lemeng Wu, Xingchao Liu, Qiang Liu, arXiv 2021 PDF, Transformer By SeonghoonYu August 02th, 2021 Summary 센트로이드 트랜스포머는 N개의 입력값을 M개의 요소로 요약합니다. 이 과정에서 필요없는 정보를 버리고 트랜스포머의 계산 복잡도를 O(MN)으로 감소합니다. M개의 요소는 Clustering의 centroid로 생각해 볼 수 있는데, 이 M개의 요소를 어떻게 선정하는 지가 핵심 아이디어로 생각해볼 수 있습니다. M개의 centroid를 선정하기 위해 입력값 x와 centroid 사이의 유사도를 측정하고 손실함수를 설계..