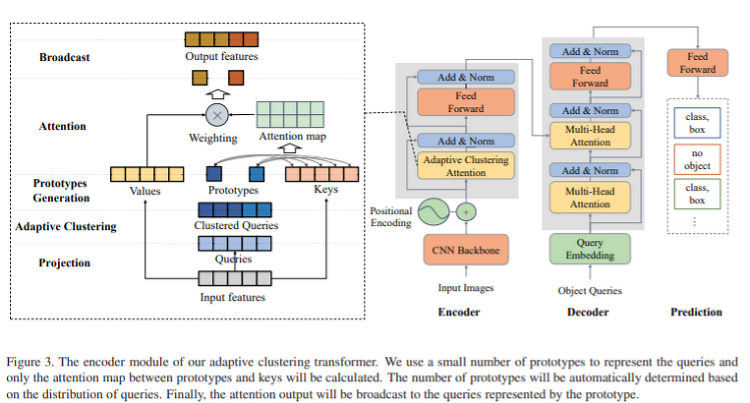
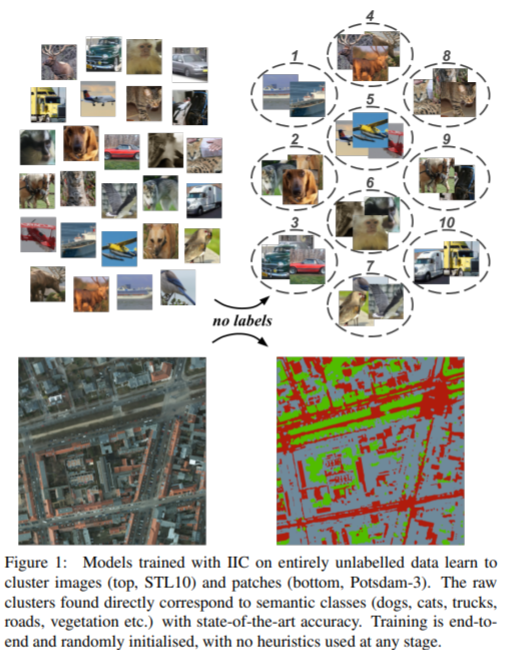
K-평균 군집화(K-Means Clustering) K-means clustering은 데이터 셋을 K개의 구별되고 겹치치 않는 cluster으로 분할하는 방법입니다. k-means clustering을 수행하기 위하여 cluster의 수 K를 정해야 합니다. 그리고나서 K-means algorithm은 각 관측값을 정확히 K개의 cluster 중 하나에 할당합니다. 아래 그림은 150개의 관측치로 구성된 데이터에 서로 다른 K값을 사용하여 K-means clustering을 수행한 결과입니다. K-means Clustering 절차 $C_1, ... C_K$를 각 cluster 내 관측치들의 인덱스들을 포함하는 집합이라고 하겠습니다. 이 집합은 두 가지 성질을 갖습니다. 1. 각 관측치는 적어도 K개 ..