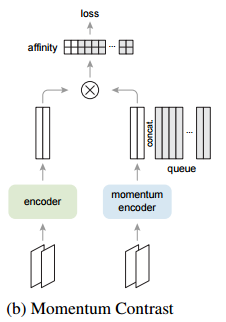
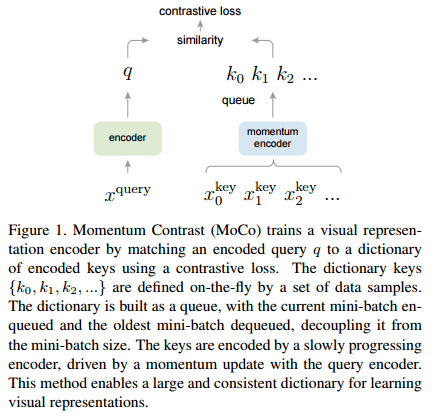
안녕하세요, 오늘 읽은 논문은 Improved Baselines with Mometum Contrastive Learning 입니다. 해당 논문은 MoCo v1에서 SimCLR의 두 가지 아이디어를 적용한 모델입니다. SimCLR은 contrastive learning에서 세 가지 핵심 요소를 제안하는데요, (1) 많은 negative sample을 사용하기 위한 large batch, longer training, (2) stronger augmentation(color distortion, random resize crop, blur), (3) MLP projection head 가 contrastive learning의 성능을 높일 수 있다는 것을 실험적으로 보여줍니다. MoCov2는 SimCLR에..