(밑바닥부터 시작하는 딥러닝, 사이토고키) 를 바탕으로 제작하였습니다.
오차역전파법 (3) - 활성화 함수, Affine, Softmax 계층 구현
이전의 포스팅에서는 사과 쇼핑 문제를 통해 간단한 역전파 계층을 구현해 보았습니다.
이번 포스팅에서는 활성화 함수(ReLu, Sigmoid) 계층, 행렬의 곱을 의미하는 Affine 계층, 출력층에서 사용하는 소프트맥스 계층을 구현해보도록 하겠습니다.
5. 활성화 함수 계층 구현하기
이제 계산 그래프를 신경망에 적용해보겠습니다. 우선 활성화 함수인 ReLu와 Sigmoid 계층을 구현하겠습니다.
5.1 ReLU 계층
활성화 함수로 사용되는 ReLU의 수식은 다음과 같습니다.

x에 대한 y의 미분은 다음처럼 구합니다.

순전파 때의 입력인 x가 0보다 크면 역전파는 상류의 값을 그대로 하류로 흘립니다. 반면, 순전파 때 x가 0 이하면 역전파 때는 하류로 신호를 보내지 않습니다.(0을 보냅니다) 계산 그래프는 아래처럼 그릴 수 있습니다.

이제 ReLU 계층을 구현해보겠습니다.
class Relu:
def __init__(self):
self.mask = None # mask 인스턴트 변수
# mask는 True/False로 구성된 넘파이 배열로,
# 순전파의 입력인 x의 원소 값이 0 이하인 인덱스는 True,
# 그 외(0보다 큰 원소)는 False로 유지합니다.
def forward(self, x):
self.mask = (x <= 0)
out = x.copy() # x를 복사
out[self.mask] = 0 # mask = True 인 인덱스를 0 으로 바꾸기
return out
def backward(self, dout):
dout[self.mask] = 0 # mask = True 인 인덱스를 0 으로 바꾸기
dx = dout
return dx
ReLU 계층은 전기 회로의 '스위치'에 비유할 수 있습니다. 순전파 때 전류가 흐르고 있으면 스위치를 ON으로 하고, 흐르지 않으면 OFF로 합니다. 역전파 때는 스위치가 ON이라면 전류가 그대로 흐르고, OFF면 더이상 흐르지 않습니다.
5.2 Sigmoid 계층
시그모이드 함수는 다음 식을 의미하는 함수입니다.

이를 계산 그래프로 그리면 아래 처럼 됩니다.

'X'와 '+'노드 말고도 'exp'와 '/'노드가 새롭게 등장했습니다. 'exp'노드는 y = exp(x) 계산을 수행하고 '/' 노드는 y = $\frac{1}{x}$ 계산을 수행합니다. 국소적 계산의 전파로 이뤄지는 것을 확인할 수 있습니다.
이제 역전파의 흐름을 오른쪽에서 왼쪽으로 한 단계씩 짚어보겠습니다.
1단계
'/'노드, 즉 y = $\frac{1}{x}$ 을 미분하면 다음 식이 됩니다.
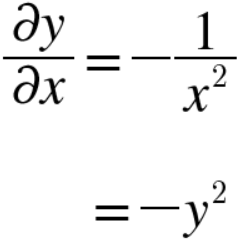
위 식에 따르면 역전파 때는 상류에서 흘러온 값에 $-y^2$(순전파의 출력을 제곱한 후 마이너스를 붙인 값)을 곱해서 하류로 전달합니다. 계산 그래프에서는 다음과 같습니다.

2단계
'+'노드는 상류의 값을 여과 없이 하류로 내보내는 게 다입니다. 계산 그래프에서는 다음과 같습니다.

3단계
'exp'노드는 y = exp(x) 연산을 수행하며, 그 미분은 다음과 같습니다.
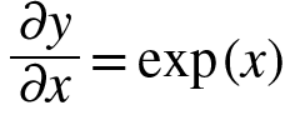
계산 그래프에서는 상류의 값에 순전파 때의 출력(이 예에서는 exp(-x))을 곱해 하류로 전파합니다.
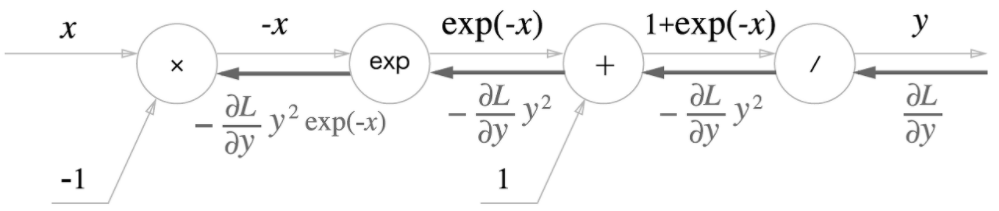
4단계
'X' 노드는 순전파 때의 값을 '서로 바꿔'곱합니다. 이 예에서는 -1을 곱하면 되겠습니다.

이상으로 Sigmoid 계층의 역전파를 계산 그래프로 완성했습니다. 그림에서 보듯이 역전파의 최종 출력인 $\frac{\partial L}{\partial y}y^2exp(-x)$ 값이 하류 노드로 전파됩니다. 여기에서 $\frac{\partial L}{\partial y}y^2exp(-x)$를 순전파의 입력인 x와 출력 y만으로 계산할 수 있습니다. 그래서 중간 과정을 모두 묶어 단순한 'sigmoid' 노드 하나로 대체할 수 있습니다.

간소화 버전은 역전파 과정의 중간 계산들을 생략할 수 있어 더 효율적인 계산입니다. 또, 노드를 그룹화하여 Sigmoid 계층의 세세한 내용을 노출하지 않고 입력과 출력에만 집중 할 수 있다는 것도 중요한 포인트입니다.
또한, $\frac{\partial L}{\partial y}y^2exp(-x)$는 다음처럼 정리해서 쓸 수 있습니다.

이처럼 Sigmoid 계층의 역전파는 순전파의 출력(y)만으로 계산할 수 있습니다.
Sigmoid 계층을 파이썬으로 구현하기
class Sigmoid:
def __init__(self): # 초기화
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
# 순전파의 출력을 인스턴스 변수 out에 보관했다가, 역전파 계산 때 그 값을 사용합니다.
def backword(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
6. Affine/Softmax 계층 구현하기
6.1 Affine 계층
어파인 변환(affine transformation)은 신경망 순전파 때 수행하는 행렬의 곱을 기하학에서 부르는 이름입니다. 어파인 변환을 수행하는 처리를 'Affine'계층 이라는 이름으로 구현합니다.
신경망 순전파 복습
신경망의 순전파에 가중치 신호의 총합을 계산하기 때문에 행렬의 곱(np.dot)을 사용했습니다. 그러면 뉴런의 가중치 합은 Y = np.dot(X, W) + B처럼 계산합니다. 그리고 이 Y를 활성화 함수로 변환해 다음 층으로 전파하는 것이 신경망 순전파의 흐름이었습니다. 행렬의 곱 계산은 대응하는 차원의 원소 수를 일치시키는 게 핵심입니다.
그럼 행렬의 곱과 편향의 합을 계산 그래프로 그려보겠습니다. 행렬의 곱을 계산하는 노드를 'dot'으로 표현했습니다. 괄호안의 숫자는 행렬의 형상을 의미합니다.

비교적 단순한 계산 그래프입니다. 단, X, W, B가 행렬(다차원 배열)이라는 점에 주의해야 합니다.
이제 역전파에 대해 생각해 보겠습니다. 식을 전개해보면 다음과 같습니다.


$W^T$는 W의 전치행렬을 뜻합니다. 전치행렬은 W의 (i, j) 위치의 원소를 (j, i)위치로 바꾼 것을 말합니다. 수식으로는 다음과 같이 쓸 수 있습니다. 전치를 한 이유는 행렬의 곱에서는 대응하는 차원의 원소 수를 일치시켜야 하기 때문입니다.
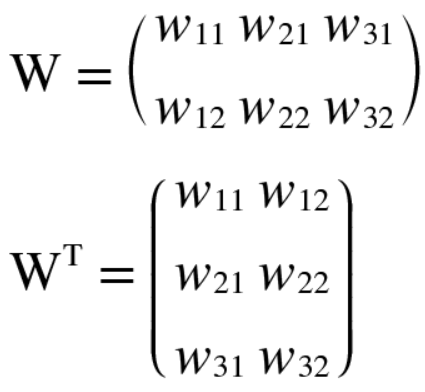
그럼 계산 그래프의 역전파를 구해보겠습니다.
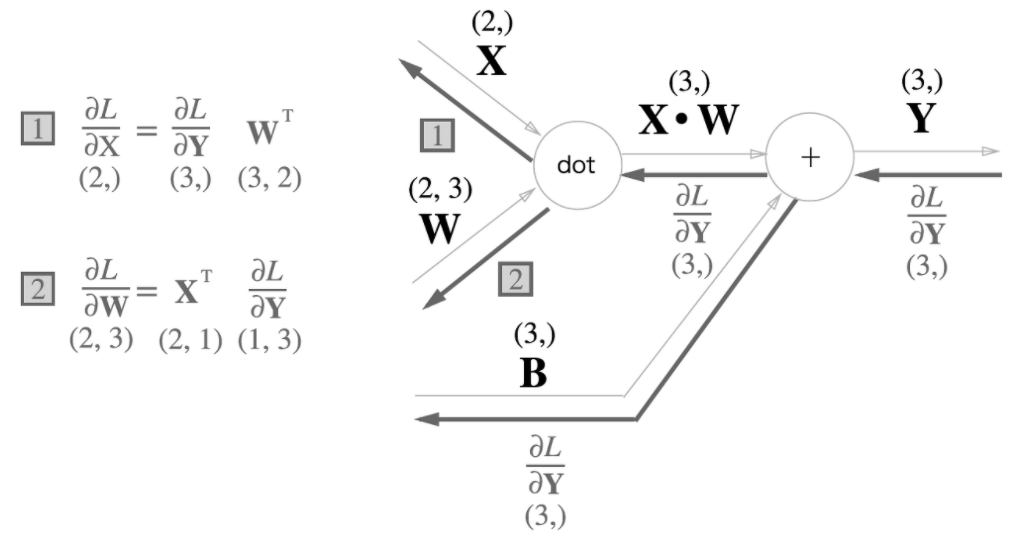
계산 그래프에서 각 변수의 형상에 주의해야 합니다. 특히 X 와 $\frac{\partial L}{\partial X}$은 같은 형상이고, W와 $\frac{\partial L}{\partial W}$도 같은 형상이라는 것을 기억해야 합니다.
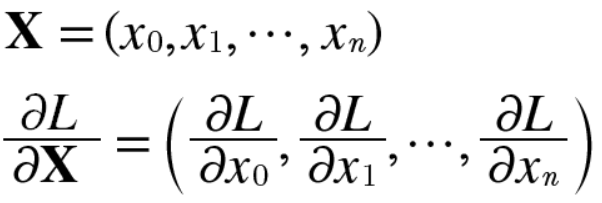
행렬 곱('dot' 노드)의 역전파는 행렬의 대응하는 차원의 원소 수가 일치하도록 곱을 조립해야 합니다. 이를 위해 W와 X를 전치해준 것입니다.

6.2 배치용 Affine 계층
지금까지 설명한 Affine 계층은 입력 데이터로 X 하나만을 고려한 것이었습니다. 이번에는 데이터 N개를 묶어 순전파하는 경우, 즉 배치용 Affine 계층을 생각해보겠습니다.
배치용 Affine 계층을 계산 그래프로 그려보겠습니다.

기존과 다른 부분은 입력인 X의 형상이 (N, 2)가 된 것 뿐입니다. 그 뒤로는 지금까지와 같이 계산 그래프의 순서를 따라 순순히 행렬 계산을 하게 됩니다. 또, 역전파 때는 행렬의 형상에 주의하면 $\frac{\partial L}{\partial X}$과 $\frac{\partial L}{\partial W}$은 이전과 같이 도출할 수 있습니다.
편향을 더할 때도 주의해야 합니다. 순전파 때의 편향 덧셈은 각각의 데이터(1번째 데이터, 2번째 데이터, ...)에 더해집니다. 그래서 역전파 때는 각 데이터의 역전파 값이 편향의 원소에 모여야 합니다. 코드로는 다음과 같습니다.
dY = np.array([ [1, 2, 3], [4, 5, 6] ])
dB = np.sum(dY, axis = 0) # axis=0은 0번째 축에 대해서 총 합을 구합니다.
# dY가 (3, 2) 이므로 0번째 축은 3을 의미
print(dB)
>>> array([5, 7, 9])
Affine 구현을 해보겠습니다.
class Affine:
def __init__(self, W, b): # 매개변수 초기화
self.W = W
self.b = b
self.x = None
self.original_x_shape = None # 입력 데이터가 텐서(4차원 데이터)인 경우도 고려
# 가중치와 편향 매개변수의 미분
self.dW = None
self.db = None
def forward(self, x):
# 텐서 대응(4차원 데이터)
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1) # -1의 의미는 원래 배열의 길이와 남은 차원으로 부터 추정입니다.
# 요소가 12개일때 shape(3,-1) 은 (3 X 4) 행렬이 됩니다.
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T) # (3)
self.dW = np.dot(self.x.T, dout) # (2)
self.db = np.sum(dout, axis=0) # (1)
dx = dx.reshape(*self.original_x_shape) # 기존의 입력 데이터 모양으로 변경(텐서 대응)
return dx
6.3 Softmax-with-Loss 계층
마지막으로 출력층에서 사용하는 소프트맥스 함수에 관해 설명하겠습니다. 이 소프트맥스 함수는 입력 값을 정규화 하여 출력합니다. 예를 들어 손글씨 숫자 인식에서의 Softmax 계층의 출력은 아래처럼 됩니다.

Softmax 계층은 입력 값을 정규화(출력의 합이 1이 되도록 변형)하여 출력합니다.
신경망에서 수행하는 작업은 학습과 추론 두 가지입니다. 추론할 때는 일반적으로 Softmax 계층을 사용하지 않습니다. 신경망 추론에서 답을 하나만 내는 경우에는 가장 높은 점수만 알면 되니 Softmax 계층은 필요 없습니다. 반면, 신경망을 학습할 떄는 Softmax 계층이 필요합니다.
이제 소프트맥스 계층을 구현할 텐데, 손실 함수인 교차 엔트로피 오차도 포함하여 'Softmax-with-Loss 계층'이라는 이름으로 구현합니다. 먼저 Softmax-with-Loss 계층의 계산 그래프를 살펴보겠습니다.

간소화한 계산 그래프를 보여드리겠습니다.
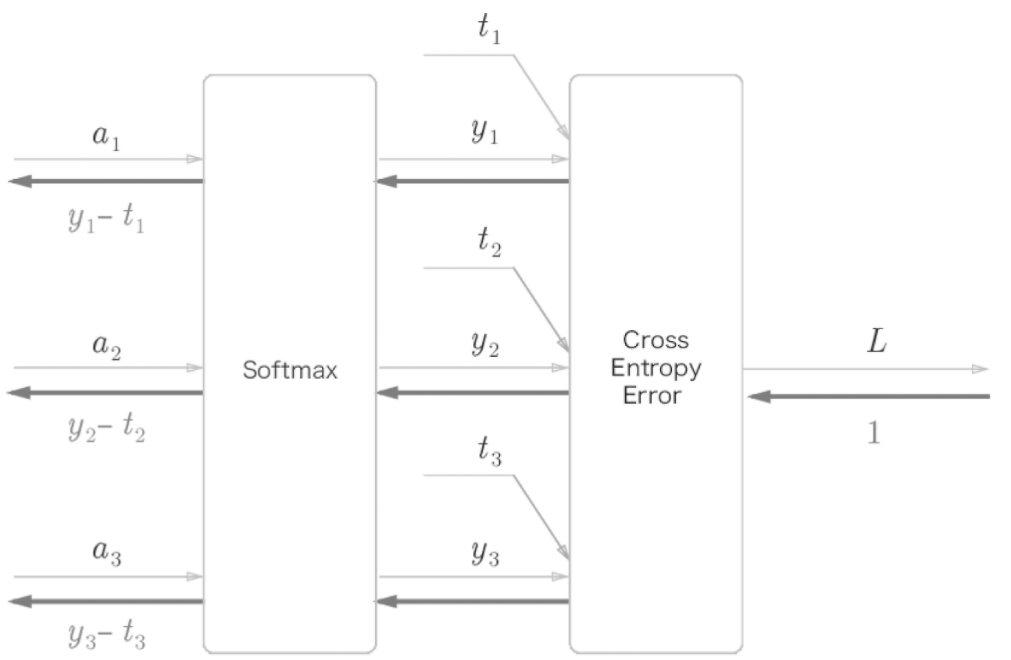
여기에서 주목할 것은 역전파의 결과입니다. Softmax 계층의 역전파는 ($y_1 - t_1$, $y_2 - t_2$, $y_3 - t_3$)라는 말끔한 결과를 내놓고 있습니다. ($y_1$, $y_2$, $y_3$)은 Softmax 계층의 출력이고, ($t_1, t_2, t_3$)은 정답 레이블 이므로 ($y_1 - t_1$, $y_2 - t_2$, $y_3 - t_3$)는 Softmax 계층의 출력과 정답 레이블의 차분인 것입니다. 신경망의 역전파에서는 이 차이인 오차가 앞 계층에 전해지는 것 입니다. 이는 신경망 학습의 중요한 성질입니다.
신경망 학습의 목적은 신경망의 출력(Softmax의 출력)이 정답 레이블과 가까워지도록 가중치 매개변수의 값을 조정하는 것이었습니다. 그래서 신경망의 출력과 정답 레이블의 오차를 효율적으로 앞 계층에 전달해야 합니다. 앞의 ($y_1 - t_1$, $y_2 - t_2$, $y_3 - t_3$)라는 결과는 신경망의 현재 출력과 정답 레이블의 오차를 있는 그대로 나타내는 것입니다.
'소프트맥스 함수'의 손실 함수로 '교차 엔트로피 오차'를 사용하는 이유
역전파의 결과가 ($y_1 - t_1$, $y_2 - t_2$, $y_3 - t_3$)로 말끔히 떨어지기 때문입니다. 교차 엔트로피 오차라는 함수가 그렇게 설계되었기 때문입니다.
'항등 함수'의 손실 함수로 '오차 제곱합'을 사용하는 이유
역전파의 결과가 ($y_1 - t_1$, $y_2 - t_2$, $y_3 - t_3$)로 말끔히 떨어지기 때문입니다.
정답 레이블이 (0, 1, 0)일 때 Softmax 계층이 (0.3, 0.2, 0.5)를 출력했다고 해봅시다. 이 경우 Softmax 계층의 역전파는 (0.3, -0.8, 0.5)라는 커다란 오차를 전파합니다. 결과적으로 Softmax 계층의 앞 계층들은 그 큰 오차로부터 큰 깨달음을 얻게 됩니다.
그럼 Softmax-with-Loss 계층을 구현해보겠습니다.
class SoftmaxWithLoss:
def __init--(self):
self.loss = None # 손실
self.y = None # softmax의 출력
self.t = None # 정답 레이블(원-핫 벡터)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size # 배치의 수로 나눠서 데이터 1개당 오차를 앞 계층으로 전파
return dx
이번 포스팅에서는 활성화함수(LeRU, Sigmoid), Affine, Softmax-with-Loss 계층을 구현하였습니다.
다음 포스팅에서는 오차역전파법을 구현한 신경망을 구축해보도록 하겠습니다. 감사합니다.
'수학 > 딥러닝 이론' 카테고리의 다른 글
| [딥러닝] 매개변수 갱신 - 확률적 경사 하강법(SGD) 개념과 단점 (0) | 2020.10.02 |
|---|---|
| 04-4 오차역전파법 (4) - 오차역전파법을 사용한 학습 구현 (0) | 2020.09.12 |
| 04-2. 오차역전파법 (2) - 간단한 역전파 계층 구현 (0) | 2020.09.12 |
| 04-1. 오차역전파법 (1) - 계산 그래프와 연쇄법칙 (0) | 2020.09.11 |
| 03-3. 신경망 학습 (3) - 학습 알고리즘 구현 (1) | 2020.09.11 |