Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
Jean-Bastien Grill, Florian Strub, Florent Altche, Corentin Tallec, Pierre H.Richemon, arXiv 2020
PDF, score [8/10], SSL By SeonghoonYu July 16th, 2021
Summary

They suggest a new approch to self-supervised learning. (1) use two network referred to as online and target network and then update target network with a slow-moving average of the online network. (2) use symmetric MSE Loss that does not require negative samples
They use Prediction method between the online network and the negative network, instead of discrimitive method between positive sample and negative samples
Achieves state of art performance compared to other unsupervised learning

Motivation
1. Contrastive methods often require comparing each example with many other examples to work well. they try to find out whether using negative pairs is necessary
2. They expect to build a sequence of representations of increasing quality by iterating procedure, using subsquent online networks as new target networks for futher training
Problem
Previous SOTA self-supervised contrastive learning requires a lot of negative samples. they requires comparing each representation of an augmented view from same image with many negative samples. So rely on batch size or memory bank. this lead to coputationally expensive.
Contribution
1. Achives SOTA performance without negatvie samples
2. BYOL is more resilient to change in batch size and in image augmentation compare to its contrastive counterparts.
Method
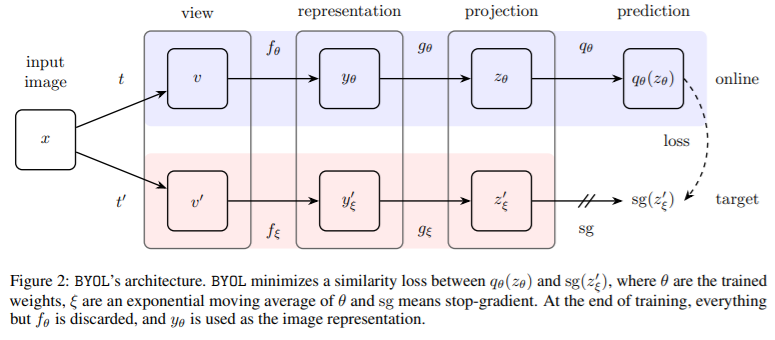
The online network consist of three parts: encoder, projector, predictor.
The target network consist of two pars: encoder, projector.
Update the target network using a moving-average of the online network

they use $\tau$ = 0.9~0.999
Target network provides the regressiong targets to train the online networks. They use symmetric MSE Loss



Experiment
- Performance under linear evaluation on ImageNet

- Semi-supervised performance using 1%, 10% labels in datasets

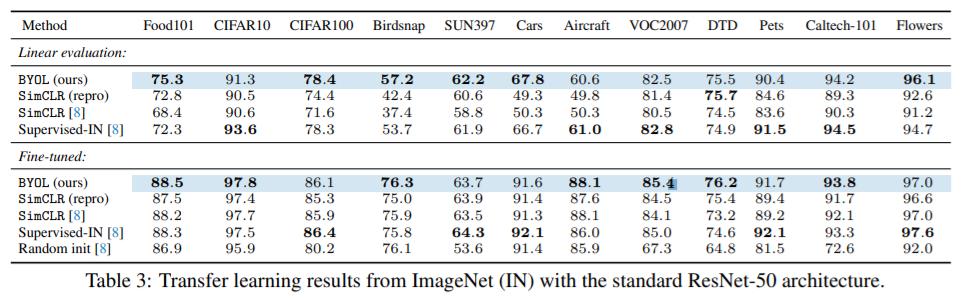
- Transfer learning to downstream task

- the effects of batch size and image augmentation

What I like about the paper
- achives sota performance without negative sample
- they illustrates the effects of batch size and trasnformation to varify BYOL's less sensitive to batch size and image augmentation
- simple framework using MSE Loss
- they use Prediction method between the online network and the negative network, instead of discrimitive method between positive sample and negative samples
my github about what i read
Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch
공부 목적으로 논문을 리뷰하고 해당 논문 파이토치 재구현을 합니다. Contribute to Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch development by creating an account on GitHub.
github.com