많은 수의 상관관계를 지닌 변수들이 존재하는 경우에 주성분 요소(Pricipal components)들은 적은 수로 변수들을 요약합니다. 따라서 주성분 요소를 활용하여 회귀를 진행하면 variance가 낮은 통계 모델을 얻을 수 있습니다.
이번 포스팅에서 공부할 주성분 분석(PCA)은 주성분 요소들을 계산하는 과정이며 주성분 요소들을 연속적으로 사용하여 데이터를 이해하는 과정입니다. 주성분 분석은 지도학습 문제에 사용하기 위한 파생 변수(derived variables)를 생성할 뿐만 아니라 데이터 시각화를 위한 도구로서 역할을 수행합니다.
주성분 분석(PCA, Principal Component Analysis)
탐색적 자료 분석(exploratory data analysis)로서 p개의 변수들에 대한 측정으로 n개의 관측값을 시각화한다고 해보겠습니다.
이는 2차원 산점도를 조사하여 구현이 가능한데 이 경우에 n개의 특징들을 2개씩 쌍으로 측정을 해야하므로 p(p-1)/2 개의 산점도가 존재합니다. 예를 들어 p=10이면 45개의 산점도가 존재합니다. p가 매우 크다면 전체 산점도를 보기는 매우 어려울 것입니다. 또한 각 data는 전체 정보에서 아주 작은 부분만을 포함하고 있기 때문에 의미있는 정보를 얻지 못할 것입니다.
따라서 정보를 가능한한 포착할 수 있는 데이터의 저차원을 찾아야 합니다. 예를 들어, 자료에 대해 대부분의 정보를 제공하는 2차원 표현을 얻는다면 저차원 공간에서 관측치들을 시각화 할 수 있습니다.
PCA는 이를 수행하기 위한 도구를 제공합니다. PCA는 분산이 가장 높은 데이터의 저차원 표현을 찾습니다. n개의 관측치들이 p개의 차원에서 존재하지만 모든 차원에 동등하게 관심이 있는 것은 아니라는 것입니다. PCA는 가능한 interesting한 적은 수의 차원을 찾는데 여기서 interesting은 관측치들이 차원을 따라 변화하는 양에 의해 측정됩니다. 즉 분산이 가장 크면 interesting하다고 말할 수 있습니다.
PCA로 찾은 각 차원들은 p 변수들의 선형 결합입니다. 이제 이 주성분(principal components)를 찾는 방식에 대하여 알아보겠습니다.
주성분을 찾는 방법
p개의 변수들의 집합 ($X_1, ... ,X_p$)의 첫 번째 주성분은 변수들의 정규화(normalized)된 선형 결합입니다.

그리고 이 첫 번째 주성분 요소의 방향은 가장 큰 분산을 갖고 있습니다. 정규화의 의미는 다음과 같습니다.

각 $\phi_{11}, ... ,\phi_{p1}$를 첫 번째 주성분의 로딩(loading)이라고 부릅니다. 로딩은 주성분 요소 로딩 벡터를 구성합니다.

로딩은 제곱의 합이 1이 되도록 제한하는데 그렇지 않으면 로딩요소들의 절대값이 임의의 큰 값이 되어 분산이 커질 수 있기 때문입니다.
n x p 크기의 데이터 셋 X가 주어진 경우에 어떻게 첫 번째 주성분 요소를 계산해야 할까요?
분산에만 관심이 있기 때문에 X내 각 변수들이 평균 0을 갖도록 중심화하였다고 가정하겠습니다. 그리고나서 아래의 형태로 가장 큰 표본 분산을 갖도록 선형 결합을 찾습니다. 그리고 z는 주성분 점수라고 부릅니다.

이는 다음의 최적화 문제를 푸는 것과 동일합니다.

위 최대로 하려는 목적 함수는 n개의 $z_{i1}$ 값의 표본 분산입니다. 이는 고유값 분해를 통해 풀 수 있습니다. 데이터 행렬에 대하여 고유값 분해(eigenvalue decomposition)를 적용하여 고유벡터(eigenvector)와 고유값(eigenvalue)을 얻습니다. 고유 벡터가 주성분 방향, 즉 주성분로딩벡터를 의미합니다. 첫 번째 고유벡터가 첫 번째 주성분 요소를 의미합니다.
첫 번째 주성분에 대한 기하학적 해석
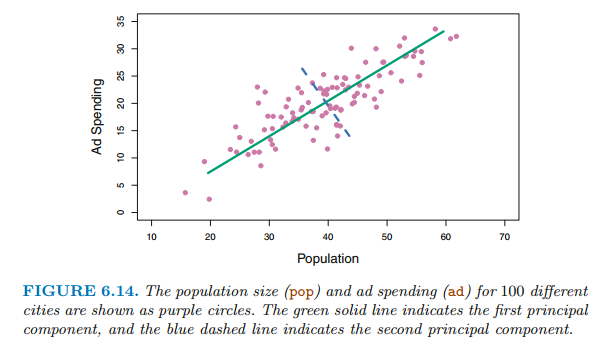
$\phi_{11}, ... ,\phi_{p1}$를 요소로 지닌 로딩 벡터 $\phi_{1}$는 변수 공간에서 데이터가 가장 크게 변화하는 방향을 정의합니다. 만약 n개의 데이터들이 이 방향으로 투영(project)하면 투영된 값들은 주성분점수 $z_{11}, ... ,z{n1}$ 그 자체 입니다.
두 번째 주성분 찾기
첫 번째 주성분 $Z_1$을 계산한 이후에 두 번째 주성분 $Z_2$를 찾을 수 있습니다. 두 번째 주성분 $Z_2$는 $Z_1$와 상관관계없이 두 번째로 큰 분산을 지닌 p개의 변수 $X_1, ... ,X_p$의 선형결합입니다. $Z_1$와 $Z_2$가 상관관계가 없으므로 두 주성분의 방향은 직교합니다.
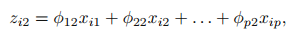
여기서 $\phi_2$는 두 번째 주성분로딩벡터라고 합니다. 두 번째 주성분로딩벡터를 찾는 방법은 위에서 살펴본 최적화 문제에서 $\phi_1$과 $\phi_2$가 직교한다는 추가 조건하에 $\phi_1$을 $\phi_2$로 대체하면 됩니다.
주성분 시각화
일단 주성분을 찾고 나면 데이터의 저차원 뷰를 생성하여 각 주성분들을 시각화 할 수 있습니다. 예를 들어, 점수 벡터 $Z_1$ 대 $Z_2$, $Z_1$ 대 $Z_3$, $Z_2$ 대 $Z_3$ 등을 그래프로 나타낼 수 있습니다. 이는 기하학적으로 원래의 데이터를 주성분 로딩 벡터에 의해 생성된 부분공간상으로 투영(Project)하여 이 투영된 점들을 그래프로 나타내는 것입니다.

위 그림은 미국의 50개 각 주에서 주민 10만명당 Assult, Murder, Rape의 각 범죄에 대한 최포횟수에 대한 PCA를 시각화한 것입니다. 주성분점수벡터 길이는 n=50이고 주성분로딩벡터 길이 p는 4입니다. PCA는 평균 0, 분산 1이 되게 표준화 한 후 수행합니다. 주성분로딩에 대한 표는 아래와 같습니다.
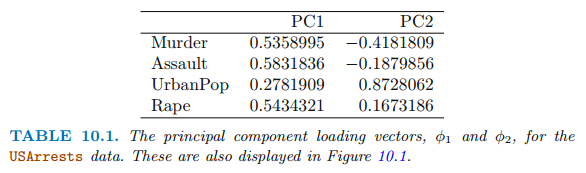
위 표에서 첫 번째 주성분로딩벡터는 Murder, Assault, Rape와 비슷한 가중치를 부여하고 UrvanPop에는 낮은 가중치를 부여합니다. 이 성분은 대략 전체 중범죄율의 측도에 대응합니다. 두 번째 주성분로딩벡터는 UrbanPop에 높은 가중치를 부여하는데 이 성분은 대략적으로 그 주의 도시화수준을 나타냅니다.
위 그림에서 첫 번째 주성분에 대해 큰 값을 갖는 California, Nevada, Florida는 범죄율이 높다는 것을 나타냅니다. California는 두 번째 주성분에 대해서도 높은 점수를 지니는데 이는 높은 수준의 도시화를 나타냅니다. 이처럼 주성분 분석을 통하여 주(state) 사이의 차이를 조사할 수 있습니다.
주성분의 다른 해석
첫 두 주성분로딩벡터를 3차원 시각화한 그림은 아래와 같습니다. 이 두 로딩 벡터는 관측치들이 가장 높은 분산을 갖는 평면을 생성(span) 합니다.
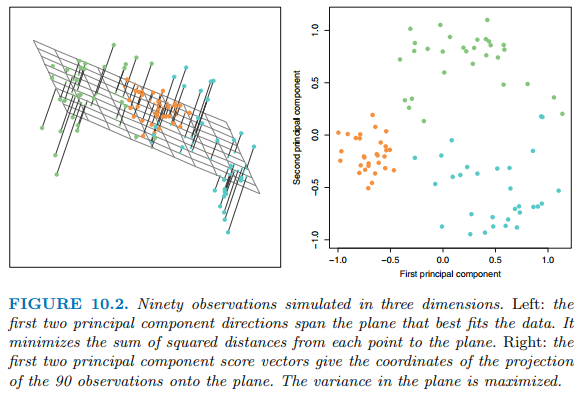
이전에 주성분 로딩 벡터는 변수 공간에서 데이터가 가장 크게 변화하는 방향이고 이 방향으로 데이터들을 투영(project)하면 주성분 점수를 얻을 수 있다는 것을 배웠습니다. 이외에도 또 다른 주성분 해석은 유용할 수 있습니다.
주성분들은 관측치와 가장 가까운 저차원 선형 표면을 제공합니다.
첫 번째 주성분 요소로딩벡터는 특별한 성질을 갖습니다. 이는 n개의 관측치와 가장 가까운 p차원 공간에서의 선입니다.

위 그림에서 점선은 각 관측값과 첫 번째 주성분 로딩 벡터 사이의 거리를 나타냅니다. 또한 첫 번째 주성분 로딩 벡터는 데이터를 가장 잘 요약하는 선이며 모든 데이터들과의 가장 가깝게 놓여진 단일 차원입니다.
이러한 해석을 활용하면 M개의 주성분 점수 벡터와 M개의 주성분 로딩 벡터는 i번째 관측치에 대한 최고의 M차원 근사를 제공합니다. 이는 다음과 같이 작성할 수 있습니다.
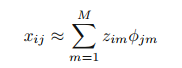
M이 충분히 클 때, M개의 주성분 점수벡터와 M개의 주성분 로딩 벡터는 데이터에 대한 가장 좋은 근사를 제공합니다.
PCA 더 알아보기
(1) 변수 스케일링(Scaling the Variables)
PCA를 수행하기 전에 변수들은 평균이 0을 갖도록 중심화(centered) 되어야 합니다. 추가적으로 PCA를 수행하여 얻어지는 결과들은 변수들이 개별적으로 scaling 되었는지에 따라 다를 것입니다. 이는 지도 학습 방법인 선형회귀의 변수에 scaling 해주는 것과는 다릅니다. 선형회귀에서 변수 c를 곱하는 것은 단순히 대응하는 계수 추정치에 1/c를 곱하는 것이 되어 얻어진 모델에 실질적인 영향을 주지 않습니다.
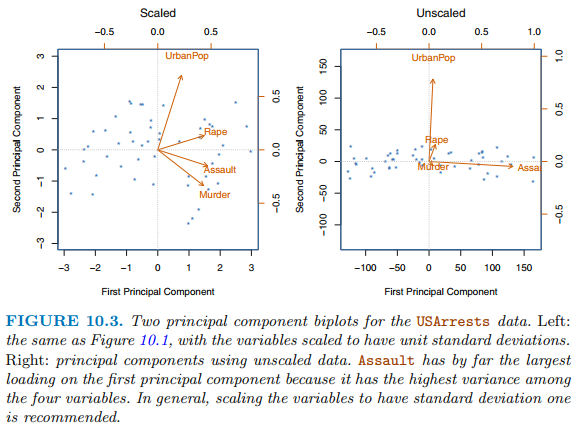
위 그림에서 PCA가 수행된 자료들의 변수들은 측정 단위가 다릅니다. 따라서 각 변수를 스케일링하여 표준편차가 1이 되게 하는 것은 중요합니다. 예를 들어, 위 그림에서 Murder, Rape, Assult는 인구 10만명당 발생 횟수이고 UrbanPop은 도심 지역에 거주하는 사람의 백분률 입니다. 위 그림을 살펴보면 scaling이 결과에 상당한 영향을 미친다는 것을 확인할 수 있습니다.
(2) 주성분의 고유성(Uniqueness of the Principal Components)
각 주성분 로딩벡터는 부호가 다를 수 있지만 고유(unique)합니다. 비슷하게 점수 벡터 또한 고유합니다. 로딩벡터와 점수벡터의 부호는 다를 수 있지만 고유합니다.
(3) 설명되는 분산의 비율(The Proportion of Variance Explained)
위 그림은 3차원 데이터 셋에 PCA를 수행한 결과입니다. 그리고 데이터의 2차원 view를 얻기 위하여 첫 두 주성분 부하 벡터에 데이터를 투사(project)하여 시각화 한 결과입니다. 3차원 데이터의 2차원 표현은 데이터에서 주요 패턴을 성공적으로 포착합니다.
관측치들을 주성분들로 투영하여 잃은 정보는 얼마나 될까요?? 즉, 주성분이 포함하고 있지 않은 데이터의 분산은 어느정도 일까요?? 일반적으로 각 주성분들의 설명되는 분산의 비율 PVE(proportion of variance explained)을 알려고 합니다.
data에 대한 전체 분산은 다음과 같이 계산할 수 있습니다.

m번째 주성분에의해 설명되는 분산은 다음과 같습니다.

m번째 주성분의 PVE는 아래 식으로 계산할 수 있습니다. PVE는 비율이므로 개별 주성분에의해 설명되는 분산 / 전체 분산 으로 계산합니다.
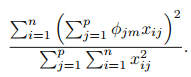
PVE의 합은 1이 됩니다.

위 그림은 각 주성분의 PVE와 누적 PVE를 나냅니다. 왼쪽 그림은 scree plot으로 알려져 있으며 이에 대해 살펴보도록 하겠습니다.
(4) 몇 개의 주성분들을 사용할지에 대한 결정
일반적으로 n x p 크기의 데이터 행렬은 min(n-1,p)개의 주성분이 존재합니다. 하지만 이 모든 주성분들을 사용하지 않습니다. 데이터를 해석하거나 시각화하기 위하여 처음 몇개의 주성분만을 사용합니다. 데이터의 좋은 이해를 위해 적은 수의 주성분을 사용하는 것이 바람직합니다.
주성분이 몇 개나 필요한지는 누적 PVE를 나타내는 scree plot를 조사하여 결정할 수 있습니다.

데이터 내 분산의 상당한 양을 설명하기 위해 필요한 가장 적은 수의 주성분을 선택하는 것이 좋습니다. 이는 위 그래프에서 각 연속된 주성분에 의해 감소하는 설명 가능한 분산의 비율의 정도를 보고 눈대중으로 결정할 수 있습니다. 이 지점을 흔히 scree plot의 elbow라고 합니다. 예를 들어 위 그림에서 첫 두 주성분은 상당한 양의 분산을 설명하고 있으며 두 번째 주성분 이후에 elbow가 존재합니다.
주성분 회귀처럼 지도 학습에서 사용하기 위한 주성분들을 계산한다면 주성분의 수를 결정하기 위한 단순한 방법이 있습니다. Cross-validation 같은 기법을 통해 주성분의 수를 조율 파라미터로 취급하여 결정할 수 있습니다.
참고자료 및 그림 출처
Gareth James의 An Introduction to Statistical Learning
'수학 > Statistical Learning' 카테고리의 다른 글
| [ISLR] K-평균 군집화(K-Means Clustering) (0) | 2021.08.06 |
|---|---|
| [ISLR] 서포트 벡터 머신(SVM, Support Vector Machine) (0) | 2021.08.03 |
| [ISLR] 비선형 결정 경계(Non-linear Decision Boundaries) (0) | 2021.08.03 |
| [ISLR] 서포트 벡터 분류기(Support Vector Classifiers) (0) | 2021.08.02 |
| [ISLR] 최대 마진 분류기(The Maximal Margin Classifier) (0) | 2021.08.02 |