Bottleneck Transformers for Visual Recognition
Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pierer Abbeel, Ashish Vaswani, arXiv 2021
PDF, Classifiction By SeonghoonYu August 10th, 2021
Summary
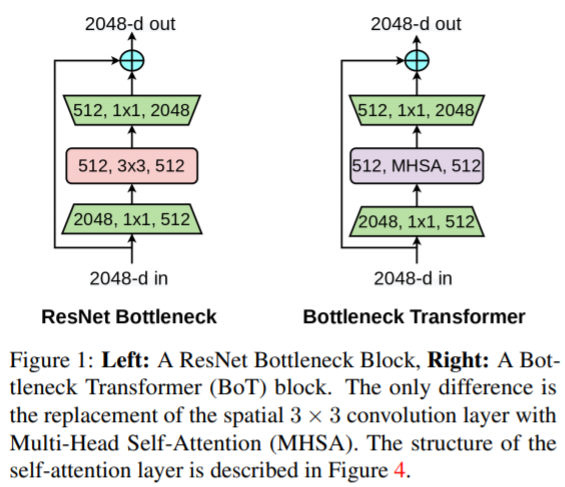
ResNet의 마지막 stage의 BottleNeck 구조에서 3x3 Conv를 Multi-Head Attention으로 대채합니다. Multi-Head Attention은 down-sampling 기능이 없으므로 stage 앞에 2x2 average pooling with stride 2를 사용하여 down sampling을 수행합니다.
왜 논문 저자는 Transformer를 ResNet 끝에 추가하려는 걸까요? Transformer를 ResNet 끝에 추가함으로써 low feature 를 통합하는 기능을 수행합니다. 또한 기존의 ViT는 연산량이 높아 고해상도(1024x1024) 이미지에서 작동하는 것은 불가능합니다. 따라서 224x224와 같은 작은 이미지 resolution만을 사용했습니다. ResNet 마지막에 TF를 추가한다면 1024x1024 와 같은 고해상도 이미지에서도 Transformer를 활용할 수 있습니다.
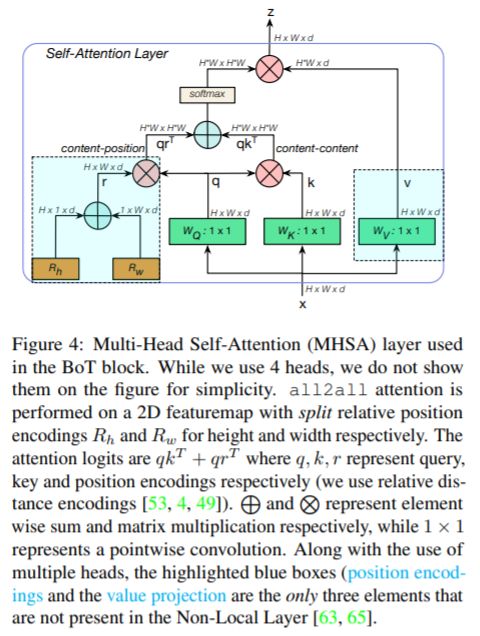
논문에서 사용하는 MHSA 세부 구조입니다. relatvie position encoding은 상대적인 2D distance를 사용합니다. relatvie position encoding은 모델의 성능을 향상시킵니다.
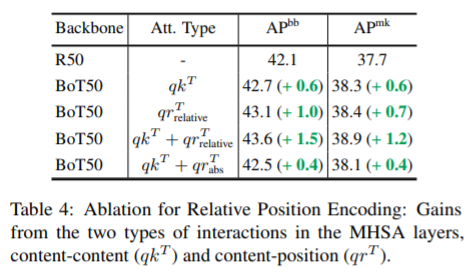

파라미터 수는 감소했는데 연산량과 inference time이 증가했습니다.
Experiment
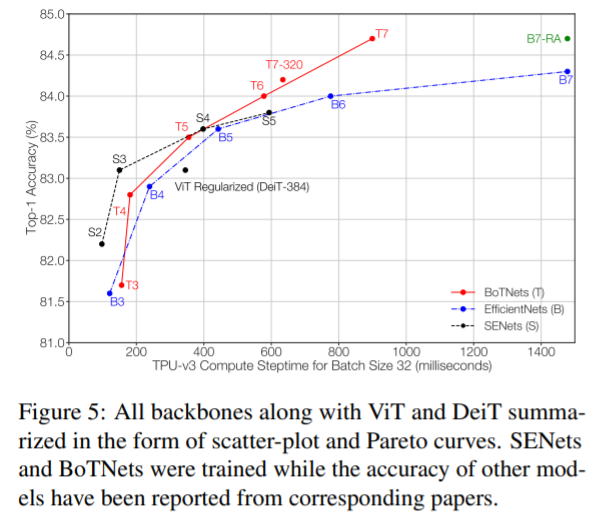

Non-local block보다 성능이 뛰어납니다.
What I like about the paper
- Transformer를 bottleNect block 사이에 끼워넣어 ResNet의 성능을 개선합니다.
my github about what i read
Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch
공부 목적으로 논문을 리뷰하고 해당 논문 파이토치 재구현을 합니다. Contribute to Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch development by creating an account on GitHub.
github.com