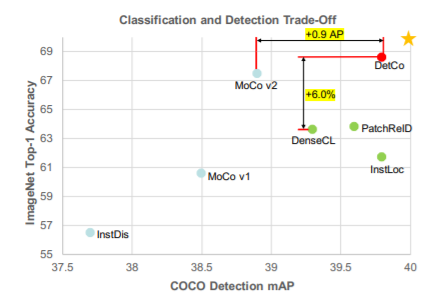
DetCo: Unsupervised Contrastive Learning for Object Detection PDF, Object Detection SSL, Enze Xie, Jian Ding, Wenhai, Xiohang Zhan, ICCV 2021 Summary DetCo는 Object Detection을 위한 SSL 방법입니다. 이전의 OD SSL 방법(DenseCL, InsLoc, PatchReID)은 detection-friendly pretext task를 위해 설계되어 OD에서 성능은 뛰어나지만 classification에서의 성능은 오히려 감소합니다. 논문에서 제안하는 DetCO는 Detection, Classification 두 task에서 높은 성능을 보이도록 pretext를 설계합니..