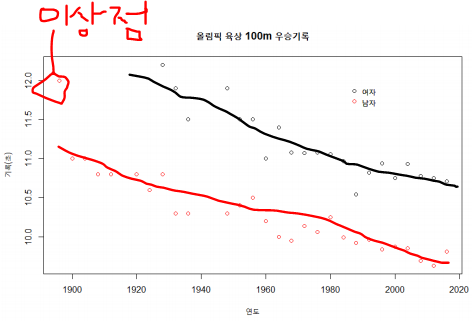
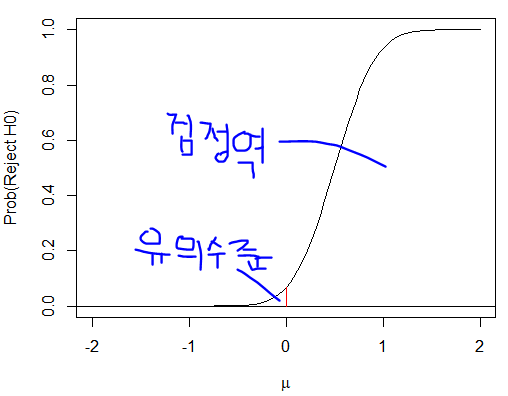
여인권 교수님의 KMOOC 강의 를 수강하면서 공부한 내용을 정리해보았습니다. 수치변수들 간의 관계를 간단히 알아보는 방법을 알아보겠습니다. 회귀 분석을 공부하기 전에 다변량 자료가 무엇인지 복습을 해보도록 하겠습니다. 다변량 자료 - Multivariate Data 다변량 자료는 어떤 대상에 대해 여러 가지 변수들을 관측(측정)한 자료들의 집함을 의미합니다 예) 신체검사 자료에서 연령, 성별, 신장, 체중 시력, 혈액형 등등 자료의 형태를 보면 변수가 여러개 인것을 확인할 수 있습니다. 이를 다변량 자료라고 합니다. 변수가 하나면 일변량 자료 입니다. 각각의 관측값 간에는 관력성이 없습니다. 이는 독립적인 관측값을 의미합니다. 다음에 배울 회귀 분석에서는 독립적인 관측값을 가정합니다. 다변량 자료에서의..