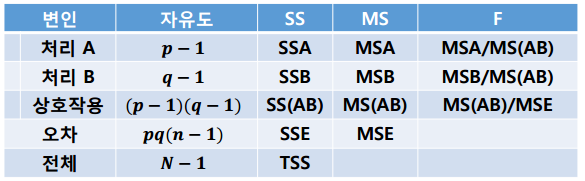
여인권 교수님의 KMOOC 강의 를 수강하면서 공부한 내용을 정리해보았습니다. 반복이 있는 이원배치 분산분석 - 변량/혼합효과모형 반복이 있는 이원배치 변량 또는 혼합효과모형에서 상호작용효과가 있는 경우의 분산분석표와 고정효과모형의 분산분석표의 차이점을 알아보겠습니다. 분산분석 결과에 따른 관심 모수에 대한 추론 방법을 알아보겠습니다. 1. 변량효과모형 (1) 변량효과 모형식 변량효과모형식은 다음과 같이 설계할 수 있습니다. 변량효과모형은 분산에 대해 관심이 있으므로 분산요소에 대한 추론을 해야합니다. (2) 평균제곱(MS)의 기댓값 변량효과모형에서는 고정효과모형과 다르게 MS를 계산합니다. 상호작용이 유의한 경우 주효과에 대한 추론은 MSE 기반이 아닌 MS(AB)을 기반으로 진행합니다. (3) 분산분..