반응형
안녕하세요, 오늘 읽은 논문은 Learning Spatiotemporal Features with 3D Convolutional Networks 입니다.
한줄 정리
video task를 3D Convolution, 3D Pooling을 사용하여 Sota 성능을 기록합니다.
Motivation
다음 4가지 성질을 만족하는 효과적인 video descriptor를 개발하려 합니다. (1) generic, (2) compact, (3) efficient, (4) Simple
Contribution
(1) 3D Conv가 appearance와 motion을 동시에 포착하여 good feature을 학습합니다.
(2) 3x3x3 Conv 구조가 효과가 좋다는 것을 실험적으로 발견합니다.
(3) 4개의 task와 6개의 benchmark에서 best 성능에 달성하거나 근접합니다.

Problem

spatial 정보를 포착하는데 특화된 2D Conv를 사용하여 Video task를 수행하는 경우에 temporal information이 소실됩니다. 이 문제점을 3D Conv를 사용하여 temporal information을 보존합니다.
Method
3D Conv와 3D Pooling을 사용하는 아래 구조(C3D)를 제안합니다.

Experiment
C3D Conv5b의 시각화

3D Conv에서 temporal depth의 실험

Sports-1M classification 결과

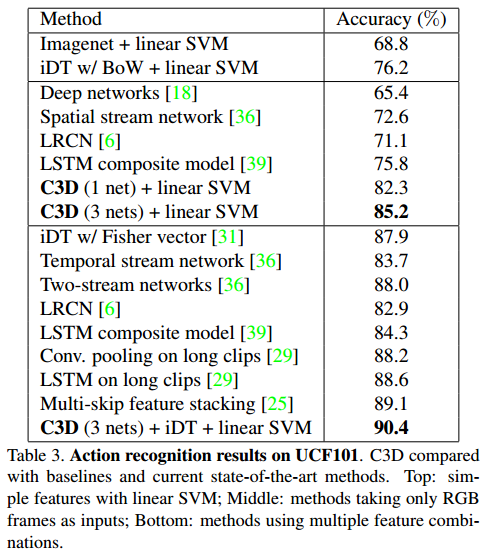
UCF101 dataset에서 Action recognition 결과
t-SNE 시각화

참고 자료
반응형