Deep Clustering for Unsupervised Learning of Visual Features
Mathilde Caron, Piotr Bojanowski, Armand Joulin, Matthijs Douze, arXiv 2018
PDF, Self Supervised Learning By SeonghoonYu July 15th, 2021
Summary

This paper is clustering based self-supervised learning in an offline fashion. This model jointly learns the parameters of a neural network and the cluster assignments of the resulting features.
They cluster the output of the ConvNet and use the subsequent cluster assignments as 'pseudo-labels' to optimize the follow equations
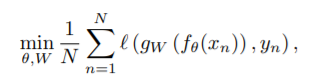
This is the standard Cross-entropy loss function between the prediction and cluster assignments. They updates the ConvNet's parameters by minimizing this loss function. Namely the model predict these cluster assignments(the pseudo labels)
They updates the cluster every epoch using the standard clustering algorithm(k-means). Clusters the outputs of ConvNet into k distinct groups based on the follow criterion.

They jointly learns a d x k centroid matrix C and the cluster assignments $y_n$ by minimizing this criterion. Solving this problem provides a set of optimal assignments $y_n$ and a centroid matrix C. These assignments $y_n$ are then used as pseudo-labels. C is not used.
This type os alternating procedure is prone to trivial solutions.
(1) Empty cluster
A discriminative model learns decision boundaries between classes. An optimal decision boundary is to assign all of the inputs to a single cluster. This issue is caused by the absence of mechanisms to prevent from empty clusters and arises in linear models as much as in convnets.
They use a common trick to prevent the empty cluster issue. When a cluster becomes empty, they randomly select a non-empty cluster and use its centroid with a small random perturbation as the new centroid for the empty cluster. Then reassign the points belonging to the non-empty cluster to the two resulting clusters
(2) Trivial parametrization
If the vast majority of images is assigned to a few clusters, the parameters will exclusively discriminate between them. So this leads to a trivial parametrization where the convnet will predict the same output regardless of the input.
A strategy to circumvent this issue is to sample images based on a uniform distibution over the classes, or pseudo-labels. This is equivalent to weight the contribution of an input to the loss function by the inverse of the size of its assigned cluster
Experiment
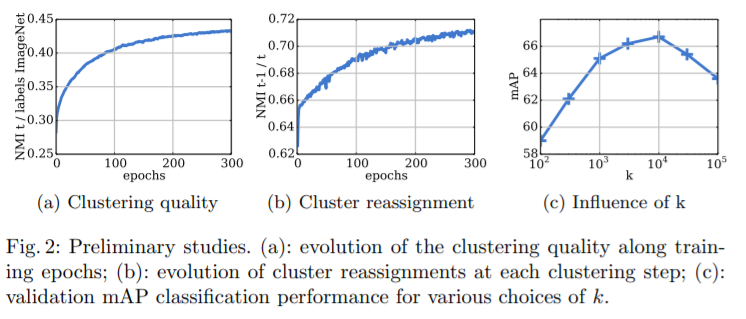
They measuer the information shared between two different assignments A and B of the same data by the Normalized Mutual Information(NMI), defined as

where I donotes the mutual information and H the entroppy. If two assignments A and B are independent, the NMI is equal to 0. if one of them is deterministically predictable from the other, the NMI is equal to 1.

What I like about the paper
- Apply the clustering algorithms to the output of ConvNet to jointly learn the parameters of model and cluster assignments.
- They suggest two method to prevent empty cluster and trivial parametrization.
- achieves SOTA performance by learning useful features on an unsupervised learning approach
my github about what i read
Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch
공부 목적으로 논문을 리뷰하고 해당 논문 파이토치 재구현을 합니다. Contribute to Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch development by creating an account on GitHub.
github.com