Learning Deep Representations by Mutual Information Estimation and Maximization
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, arXiv 2018
PDF, SSL By SeonghoonYu July 21th, 2021
Summary
This paper updates model's parameters by maximizing mutial information between immediate feature maps and flattened last feature maps obtained from ConvNet. To do this, they use Jensen-Shannon divergence(JSD) to calulating mutual information and formulate global matual information, feature mutual information and prior matching to calculate loss function.

we maximize the mutual information between MxM feature map and Feature vector using JSD.
(1) Use JSD to calulate mutual information

T is discriminator, x is m x m size immediate feature map, E is encoder, sp is softplus, x' is m x m size immediate feaure map from different images in batch.
I can implement JSD as the following pytorch pseudo-code
Ej = -F.softplus(-self.discriminator(Y, M)).mean()
Em = -F.softplus(-self.discriminator(Y, M_facke)).mean()
loss = (Em - Ej)
(2) Deep InfoMax with global ML

Pass both the high-level feature vector(Y) and the lower-level MxM feature map through a discriminator to get the score. MxM feature map from different images is Fake sample and this is used for calculating the global mutual information

(3) Deep infoMax with Local ML
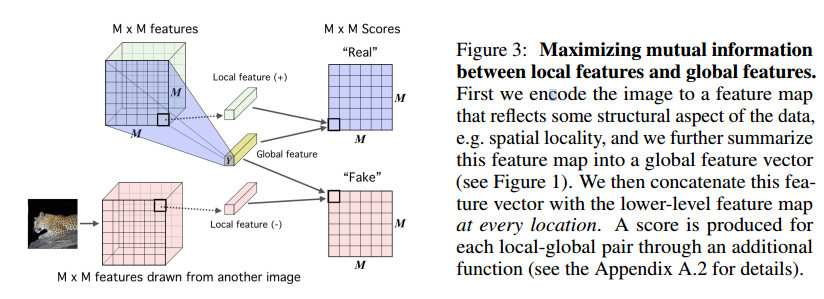
They summarize local feature map into a gloval feature using 1x1 conv or fc layer

Then, they maximize the average MI between the local features and the global feature
(4) Matching representations to a prior distribution
They discriminate between a prior MxM feature map refered to 'Real' and fake MxM feature map from different images. Diiscriminator is updated by minimizing the follow divergence.
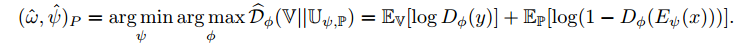
(5) Total Loss
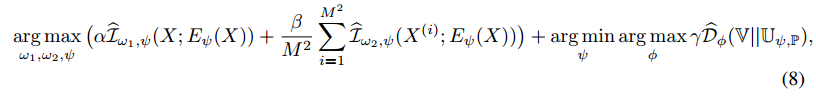
All three objectives(global and local MI maximization and prior matching) can be used together.
Experiment
Comparison with other methods
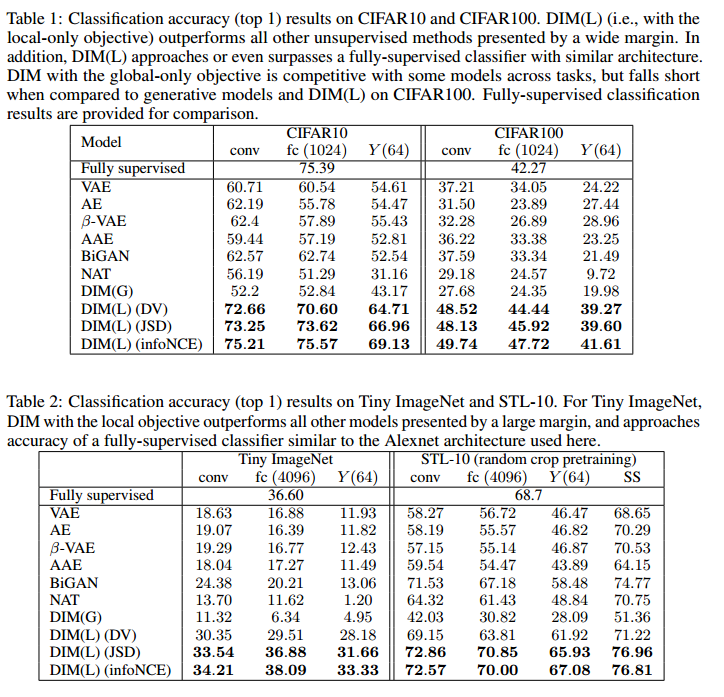

JSD is less sensitive to batch size than InfoNCE Loss

What I like about the paper
- Interasting method maximizing the mutual information between the input data and the output of encoder
my github about what i read
Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch
공부 목적으로 논문을 리뷰하고 해당 논문 파이토치 재구현을 합니다. Contribute to Seonghoon-Yu/Paper_Review_and_Implementation_in_PyTorch development by creating an account on GitHub.
github.com