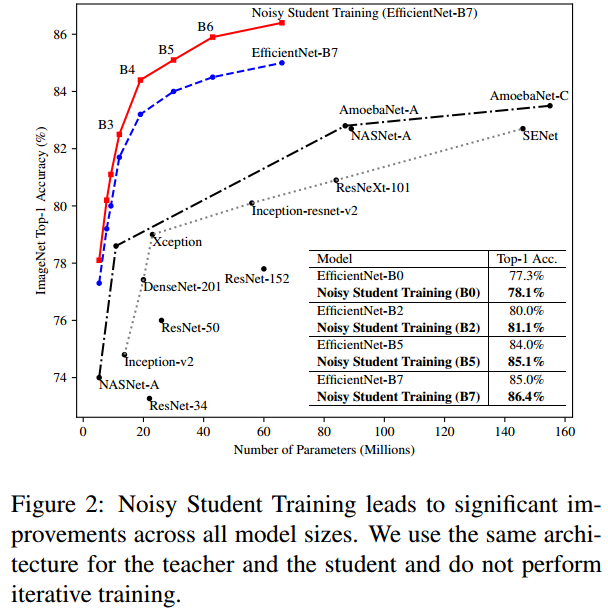
안녕하세요! 이번에 읽어볼 논문은 현재, Classification 분야에서 SOTA를 차지하고 있는 Meta Pseudo Labels 입니다. Meta Pseudo Labels는 semi-supervised learning 기법으로 SOTA를 달성했습니다. Noisy Student에서의 단점을 개선했는데요. Noisy Student가 무엇인지 살펴보겠습니다. Noisy Student Noisy Student에는 labeled image로 teacher를 학습시키고, teacher로 unlabeled image에 대한 pseudo label를 생성합니다. teacher로 생성한 pseudo labeled image와 labeled image로 student를 학습합니다. 이 student를 teacher..