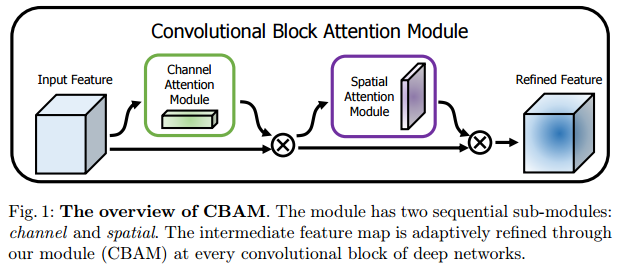
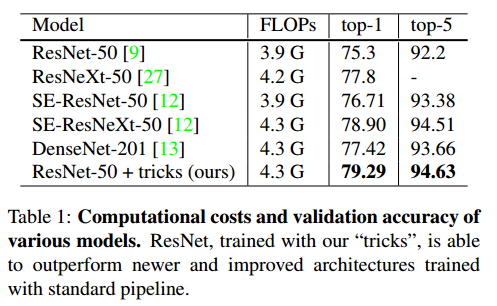
안녕하세요, 오늘 읽은 논문은 Big Transfer(BiT): General Visual Representation Learning 입니다. BiT는 large supervised dataset에 대하여 pre-training을 한 뒤에 target task에 모델을 fine-tunning합니다. 300M 이미지를 갖고 있는 JFT dataset으로 pre-training 하고, 20개 dataset에 대해 fine-tunning하여 강력한 성능을 나타냅니다. 즉, 엄청난 크기의 dataset으로 학습된 모델을 여러 task에 transfer 합니다. Big Transfer (1) Upstream Pre-Training pre-training에서 dataset size, 모델 size가 미치는 역할을 ..