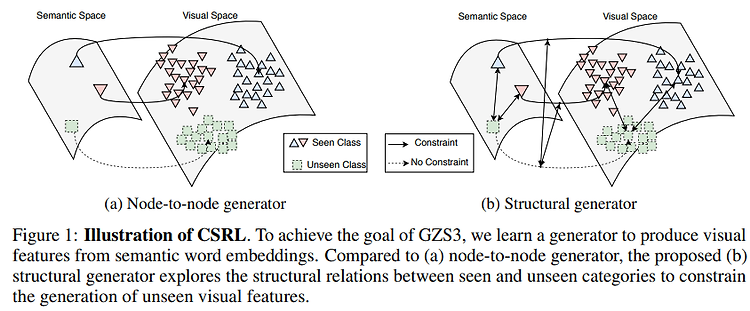
Zero-shot Learning via Shared-Reconstruction-Graph Pursuit PDF, Zero-Shot Classification, Zhao et al, arXiv 2017 Summary space shift problem을 정의한다. image feature space, attribute space, word vector space 사이의 knowledge structure가 다르다는 문제점이다. 기하학적인 inconsistent가 발생한다는 것인데, 각 space에서 structure가 서로 다른 데이터로 학습되기 때문에 발생한다. 즉, word embedding의 class 관계를 직접 image space로 transfer하면 문제점이 발생한다는 것. 논문에서 제안하는..